
Quand je prépare une migration vers le cloud, je commence toujours par la même question: quel niveau d’interruption l’entreprise peut-elle vraiment tolérer? AWS Database Migration Service sert précisément à déplacer des bases vers AWS en limitant l’arrêt, en répliquant les changements en continu et, dans les migrations hétérogènes, en accompagnant aussi la conversion de schéma. Dans ce guide, je détaille ce que le service fait réellement, comment choisir le bon mode de migration, ce qu’il faut sécuriser et les erreurs qui font perdre du temps au moment de la bascule.
Ce qu’il faut retenir avant de lancer une migration de base vers AWS
- Le service gère surtout le transfert de données et la réplication continue, pas la refonte complète d’une application.
- Le mode full load + CDC est souvent le meilleur compromis pour une base de production.
- Pour une migration entre moteurs différents, la conversion de schéma devient aussi importante que la copie des données.
- Serverless simplifie l’exploitation, mais il impose des limites concrètes, notamment sur certains cas d’usage réseau et sur les vues.
- La sécurité, les droits IAM et la stratégie réseau doivent être cadrés avant le premier flux de données.
Ce que fait réellement le service de migration vers AWS
Je vois souvent la même erreur: croire qu’un outil de migration fait tout le travail à lui seul. En pratique, AWS DMS orchestre le déplacement des données entre une source et une cible à travers des endpoints, puis exécute une tâche qui peut charger les données existantes, appliquer les changements en cache et continuer la réplication des modifications en continu. Ce n’est pas un remplaçant de projet de migration; c’est le moteur d’exécution qui rend le projet viable.
Le point important, c’est que le service ne se limite pas à un simple copier-coller. Il peut répondre à des besoins très différents: reprise d’activité sur une nouvelle base, migration vers Amazon RDS ou Aurora, alimentation d’un lac de données dans S3, ou encore alimentation analytique vers Redshift. Autrement dit, il couvre à la fois des scénarios opérationnels et des scénarios data, mais il ne transforme pas une architecture mal pensée en migration sans risque.
Quand la migration est homogène, par exemple d’un moteur PostgreSQL vers un autre environnement compatible, le travail est relativement direct. Quand elle est hétérogène, le vrai sujet devient la compatibilité des objets SQL, des fonctions, des types de données et des dépendances applicatives. C’est là que la préparation du schéma prend autant d’importance que la réplication elle-même. Cette distinction mène naturellement au choix du mode de migration, qui détermine le niveau d’arrêt accepté.
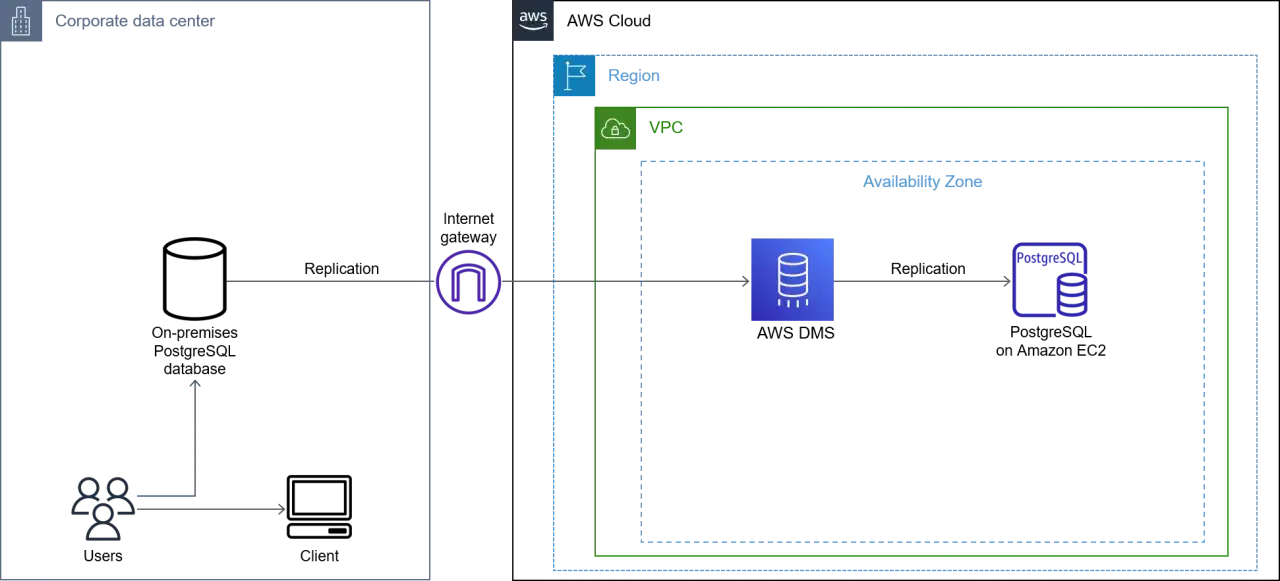
Choisir le bon mode de migration selon le temps d’arrêt acceptable
Le service s’appuie sur trois approches de migration, et je ne les choisis jamais au hasard. Le bon mode dépend du volume de données, de la fenêtre de maintenance et de la capacité de l’équipe à basculer l’application sans stress.
| Mode | Ce qu’il fait | Quand je le choisis | Limite principale |
|---|---|---|---|
| Full load | Copie l’existant vers la cible | Nouvelle base vide, ou fenêtre d’arrêt acceptable | Ne suit pas les changements pendant la copie |
| Full load + CDC | Copie l’existant puis réplique les changements en continu | Migrations de production avec arrêt très court | Demande un contrôle précis de la réplication et de la bascule |
| CDC only | Réplique seulement les changements | Base cible déjà préchargée, ou synchronisation continue | Ne prépare pas la donnée initiale |
Dans la plupart des projets réels, je privilégie full load + CDC. C’est le mode le plus utile quand une application reste en production pendant que la cible se remplit. DMS commence alors par charger la base, puis applique les changements capturés sur la source jusqu’au moment de la bascule, c’est-à-dire le cutover, le point où l’application pointe définitivement vers la nouvelle base.
Un détail opérationnel compte souvent plus qu’on ne le croit: si des transactions sont encore ouvertes au démarrage du chargement initial, le service attend par défaut 600 secondes, soit 10 minutes, avant de démarrer le full load. C’est sain pour la cohérence, mais il faut le savoir pour ne pas interpréter ce délai comme un dysfonctionnement. Une fois ce cadre posé, le vrai sujet devient la compatibilité des objets et du schéma.
Quand la conversion de schéma devient le vrai sujet
Sur une migration hétérogène, je considère la conversion de schéma comme une étape à part entière, pas comme un simple bonus. DMS Schema Conversion évalue la complexité de la migration, convertit les schémas et la majorité des objets de code, puis applique ce qui a été converti sur la cible. Il couvre notamment les tables, les vues, les procédures stockées, les fonctions, les types de données et les synonymes. Ce qui ne peut pas être traduit automatiquement est clairement signalé, ce qui évite les mauvaises surprises au moment de la recette.
Le fonctionnement interne est assez propre: on travaille avec des profils d’instance, des fournisseurs de données et des projets de migration. Pour le pilote technique, c’est utile, parce qu’on ne mélange pas les identifiants, les paramètres réseau et les règles de conversion dans un seul bloc opaque. Je trouve ce découpage plus sain qu’une migration improvisée au fil de l’eau, surtout dans des environnements où les objets SQL sont nombreux ou anciens.
Il faut aussi être lucide sur les limites. DMS Schema Conversion est la version web de l’outil AWS SCT, mais elle offre moins de plateformes supportées et des possibilités plus restreintes que l’application desktop. Si le projet touche un entrepôt de données, des frameworks big data, du SQL applicatif ou des processus ETL, je regarde toujours si AWS SCT est plus adapté. Et en 2026, je n’installerais pas un nouveau plan autour de Fleet Advisor sans vérifier le calendrier de support: AWS a annoncé sa fin de support le 20 mai 2026, donc je le traite comme un élément à ne pas surdimensionner dans un projet neuf. Une fois la conversion clarifiée, le vrai arbitrage devient souvent l’exploitation quotidienne du service.
Serverless ou instance gérée, le choix qui change l’exploitation
Le mode Serverless est séduisant parce qu’il retire une grande partie de l’administration: provisionnement automatique, mise à l’échelle, haute disponibilité intégrée et facturation à l’usage. AWS DMS Serverless supprime aussi le travail de capacité, de provisioning, d’optimisation de coût et de patching du moteur de réplication. Sur un projet dont la charge varie beaucoup, c’est un avantage très concret.
| Critère | Instance gérée | Serverless |
|---|---|---|
| Exploitation | Tu choisis et dimensionnes l’instance | Le service ajuste la capacité automatiquement |
| Facturation | Instance de réplication + stockage journalisé | Paiement à l’usage, à l’heure |
| Idéal pour | Charges stables, prévisibles, avec besoin de contrôle fin | Charges variables, migrations ponctuelles, environnements d’équipe réduite |
| Points de vigilance | Dimensionnement et supervision à la main | Pas d’IP publique, pas de vues, pas de point de départ CDC personnalisé |
Je recommande Serverless quand l’équipe veut réduire la charge d’exploitation et que le périmètre est compatible avec ses limites. Il faut notamment prévoir des VPC endpoints pour certains services comme S3, Kinesis, Secrets Manager, DynamoDB, Redshift ou OpenSearch Service. Le service Serverless n’a pas d’adresse IP publique pour l’administration, ce qui renforce l’isolement réseau, mais oblige aussi à penser proprement les dépendances internes.
À l’inverse, l’instance gérée reste plus lisible quand on veut garder la main sur le dimensionnement, tester finement le comportement ou gérer des cas plus particuliers. Pour un pilote, je pars volontiers d’une petite instance comme dms.t3.micro, qui offre 2 vCPU et 1 GiB de mémoire, simplement pour valider la connectivité et le mapping des objets. Pour des flux soutenus, je monte plus haut sans hésiter. Cette question d’exploitation renvoie directement à la sécurité, qui ne doit jamais être un post-scriptum.
Sécurité, réseau et conformité à verrouiller avant le premier flux
Dans un projet de migration, je traite la sécurité comme une exigence de conception, pas comme une vérification de fin de parcours. Les endpoints source et cible doivent être protégés, les identités IAM doivent suivre le principe du moindre privilège, et les secrets de connexion ne doivent pas circuler en clair. Si le projet est sensible, je fais aussi valider en amont la manière dont les journaux, les artefacts de conversion et les fichiers intermédiaires sont stockés et chiffrés. Le réseau compte autant que les droits. J’évite d’exposer les bases sources à Internet quand ce n’est pas strictement nécessaire, je garde les flux dans des sous-réseaux privés et je vérifie les groupes de sécurité avant d’ouvrir la moindre liaison. Avec Serverless, cette discipline est encore plus importante, parce que certaines dépendances passent obligatoirement par des points d’accès privés. C’est souvent à cette étape que l’on voit si l’architecture a été pensée comme un ensemble cohérent ou comme une juxtaposition de décisions rapides.Sur les projets soumis à des contraintes de conformité, je regarde aussi la traçabilité: qui a créé la tâche, qui a modifié la configuration, où vont les données intermédiaires, et comment le cutover est documenté. En informatique et en cybersécurité, la migration n’est pas seulement un mouvement technique; c’est aussi un changement de surface d’exposition. Une fois ce cadre posé, les erreurs à éviter deviennent beaucoup plus visibles.
Les erreurs qui font déraper un projet de migration
Les mêmes causes reviennent souvent, et elles coûtent cher parce qu’elles sont évitables. La première erreur consiste à sous-dimensionner la réplication, puis à découvrir trop tard que le volume réel de transactions n’a rien à voir avec celui du test. La deuxième consiste à ignorer les index, les contraintes référentielles et les triggers pendant le chargement initial, alors qu’ils peuvent ralentir ou perturber le processus. Pour un full load, je préfère souvent reporter leur création; pour un full load + CDC, je veille à ce que les index secondaires utiles soient en place avant la phase CDC.
Une autre erreur classique, c’est de croire que tout ce qui existe sur la source sera automatiquement prêt sur la cible. Ce n’est pas vrai. Certains objets doivent être adaptés ou réécrits, surtout quand on change de moteur. J’ai vu des projets dériver simplement parce qu’on avait traité les procédures stockées comme de la donnée, alors qu’elles font partie de la logique applicative. C’est précisément là qu’un outil de conversion de schéma mérite une vraie revue humaine.
- Je teste toujours la réplication avec un jeu de données représentatif, pas avec une base trop propre.
- Je vérifie les droits sur la source avant de lancer le premier flux, surtout en lecture de logs pour le CDC.
- Je valide les objets non convertis dès la phase d’analyse, pas à la veille du cutover.
- Je prépare la fenêtre de bascule comme une opération à part entière, avec retour arrière si nécessaire.
- Je nettoie les ressources après migration pour éviter les coûts résiduels et les accès oubliés.
Quand ces erreurs sont anticipées, la migration cesse d’être une succession de contournements. Elle devient un projet pilotable, avec des jalons clairs et une charge d’exploitation beaucoup plus maîtrisable.
Ce que je recommande pour un projet mené proprement en 2026
Si je devais résumer ma méthode, je la réduirais à quatre gestes simples: analyser le schéma, choisir le bon mode de migration, sécuriser le réseau et répéter la bascule avant de toucher à la production. Dans les projets les plus sereins, le service ne sert pas seulement à déplacer des données; il structure la migration autour d’une séquence lisible, depuis l’évaluation jusqu’à la mise en service de la cible.
Je ne traite plus AWS Database Migration Service comme un simple outil de copie, mais comme un chaînon d’orchestration qui exige un vrai cadrage projet. C’est cette discipline qui évite les surprises de schéma, les temps d’arrêt plus longs que prévu et les migrations qui paraissent réussies jusqu’au premier pic de charge. Si la base est complexe, je conseille de démarrer par un pilote, de documenter les objets non convertis et de valider le chemin réseau avant de penser performance pure.
En pratique, la réussite tient moins à la promesse du service qu’à la qualité des choix en amont. Quand le mode de migration, la sécurité, la conversion de schéma et le plan de cutover sont alignés, la migration vers AWS devient nettement plus prévisible, et c’est exactement ce qu’on cherche dans un projet IT sérieux.