
L’architecture 3 tiers reste un bon point de départ quand une application doit grandir sans perdre en lisibilité ni en contrôle. En séparant l’interface, la logique métier et les données, on gagne en maintenance, en sécurité et en capacité d’évolution, à condition de respecter des frontières nettes entre les couches. Je détaille ici ce que chaque couche fait réellement, comment ce modèle aide la cybersécurité, et dans quels cas il vaut mieux le compléter ou le remplacer.
Ce qu’il faut retenir d’une architecture à trois couches
- Elle sépare présentation, logique applicative et données pour réduire le couplage.
- Son intérêt principal est la maintenabilité, la montée en charge ciblée et la réduction de la surface d’attaque.
- Elle convient bien aux applications métier, aux portails web et aux systèmes qui doivent rester gouvernables dans le temps.
- Le vrai risque vient moins du modèle que d’une séparation mal appliquée entre les couches.
- Une bonne mise en œuvre repose sur des flux réseau maîtrisés, des droits minimaux et une observabilité solide.
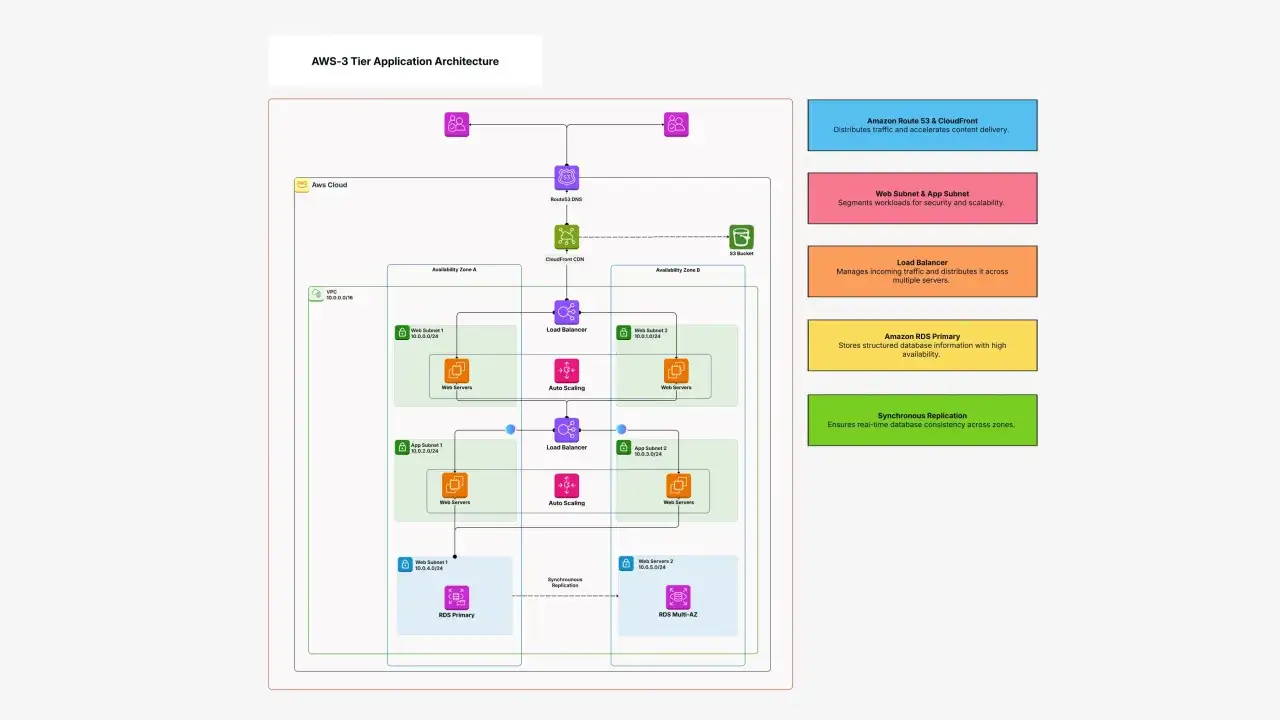
Ce que recouvre vraiment le modèle à trois couches
Selon IBM, une architecture à trois couches organise l’application autour de trois responsabilités distinctes: la présentation, le traitement applicatif et la gestion des données. Dit simplement, l’utilisateur voit la première couche, la logique métier vit au milieu, et la base de données reste en arrière-plan. C’est simple à énoncer, mais la valeur du modèle se joue dans la discipline avec laquelle on respecte ces frontières.
Lire aussi : Licences open source - Guide complet pour bien choisir
Layer et tier ne se confondent pas
Je vois souvent une confusion entre couche logique et tier physique. Une layer décrit une responsabilité fonctionnelle, alors qu’un tier désigne l’endroit où cette responsabilité est exécutée. On peut donc avoir trois couches logiques réparties sur deux tiers physiques, par exemple quand l’application et la présentation partagent le même serveur au début d’un projet.
| Couche | Rôle principal | Ce qu’elle doit éviter | Risque si elle déborde |
|---|---|---|---|
| Présentation | Afficher, collecter les saisies, gérer l’expérience utilisateur | Contenir des règles métier lourdes | Interface difficile à faire évoluer |
| Application | Orchestrer les cas d’usage, appliquer les règles métier, gérer les transactions | Parler directement à l’utilisateur ou au stockage sans abstraction | Logique dispersée et peu testable |
| Données | Stocker, interroger, sécuriser et restaurer l’information | Décider du comportement métier ou de l’UI | Base trop couplée au reste du système |
Ce découpage devient vraiment utile quand on regarde son impact sur la sécurité, car c’est là que les bénéfices cessent d’être théoriques.
Pourquoi ce découpage change vraiment la sécurité
En cybersécurité, l’intérêt du modèle tient surtout à l’isolement. La couche de présentation peut être exposée au réseau public, la couche applicative peut rester dans une zone plus fermée, et la couche de données peut être encore plus protégée. Microsoft Learn rappelle d’ailleurs qu’un modèle N-tier sert précisément à séparer les responsabilités logiques et les tiers physiques pour mieux contrôler les flux et les zones de confiance.
J’ajoute un autre point essentiel: la logique du moindre privilège. AWS le formule clairement dans ses recommandations de sécurité, et c’est exactement la bonne lecture ici. Chaque service, compte ou identité technique ne doit obtenir que les droits strictement nécessaires, rien de plus. Dans une architecture mal pensée, on donne souvent trop d’accès à la couche applicative “pour que ça marche”, puis on s’étonne plus tard de l’ampleur d’une compromission.
| Couche | Contrôles utiles | Effet recherché |
|---|---|---|
| Présentation | TLS, WAF, filtrage d’entrée, protection anti-bot, validation minimale | Réduire l’exposition directe aux attaques web |
| Application | Authentification forte, autorisation fine, coffre à secrets, limitation de débit, journaux structurés | Empêcher qu’un accès frontal donne trop de levier |
| Données | Réseau privé, chiffrement au repos et en transit, comptes de service restreints, sauvegardes testées | Limiter l’impact d’un vol d’identifiants ou d’une erreur applicative |
Le point clé, à mes yeux, est simple: une bonne séparation ne sert pas seulement à “faire propre”, elle aide aussi à contenir une faille. Et c’est précisément ce qui permet de décider quand ce modèle vaut le coup, et quand il devient trop rigide.
Quand ce modèle est le bon choix
Je recommande souvent une architecture à trois couches pour une application métier classique, un portail client, un intranet ou un système transactionnel qui doit durer. C’est un compromis solide entre clarté, sécurité et coûts d’exploitation. On garde une structure compréhensible par l’équipe, tout en se laissant la possibilité de faire évoluer chaque partie séparément.
| Option | Quand je la conseille | Avantage | Limite |
|---|---|---|---|
| Architecture à trois couches | Application métier stable ou en croissance, besoin de séparation nette | Bon équilibre entre lisibilité, sécurité et évolutivité | Ajoute un peu de latence et demande de la discipline |
| Monolithe | Produit simple, équipe réduite, besoin de livrer vite | Très peu de complexité opérationnelle | Peut devenir difficile à faire évoluer si le périmètre grossit |
| Microservices | Grande équipe, domaines distincts, besoins de déploiement indépendants | Scalabilité organisationnelle et technique plus fine | Surcoût important en orchestration, supervision et sécurité |
Je ne pousserais pas une architecture plus distribuée que nécessaire si le projet reste flou, l’équipe petite ou le risque métier limité. À l’inverse, si plusieurs équipes travaillent sur le même socle, si les contraintes de sécurité montent ou si le trafic devient plus sérieux, la séparation en couches devient vite un choix pragmatique. La question suivante est alors moins “faut-il séparer ?” que “où se trompe-t-on le plus souvent ?”.
Les erreurs qui cassent le modèle en production
Les problèmes que je rencontre le plus ne viennent pas de l’architecture elle-même, mais de sa mauvaise exécution. Une architecture bien dessinée sur un schéma peut devenir fragile en quelques semaines si les équipes la contournent dans le code ou dans le réseau.
- Faire parler l’interface directement à la base : on gagne du temps au début, puis on perd toute cohérence métier et toute maîtrise de sécurité.
- Répartir les règles métier partout : un peu dans le front, un peu dans l’API, un peu dans SQL. Le résultat devient imprévisible et difficile à tester.
- Donner trop de droits à la couche applicative : c’est pratique pour livrer, mais c’est exactement le genre de raccourci qui amplifie une faille.
- Multiplier les allers-retours réseau : la couche applicative finit par compenser un mauvais design en appelant trop souvent les autres composants.
- Négliger l’observabilité : sans logs corrélés, métriques et traces, on ne sait plus quelle couche a cassé ni pourquoi.
- Laisser les secrets dans le code ou les variables non protégées : c’est encore trop courant, et cela transforme une faiblesse technique en incident de sécurité.
Le plus frustrant, c’est que ces erreurs sont rarement spectaculaires au départ. Elles s’accumulent, puis coûtent cher au premier changement de périmètre ou au premier incident. Une fois ces pièges identifiés, la mise en place du modèle devient beaucoup plus simple à cadrer.
Comment je le mets en place sur un projet métier
Quand je dois structurer un projet autour de trois couches, je commence par les frontières, pas par les outils. Le choix des frameworks, des bases ou du cloud vient après. Sinon, on fige trop tôt des décisions qui devraient rester guidées par le besoin métier.
- Je définis les contrats entre les couches : objets d’échange, API, formats de réponse, erreurs, versioning. Sans contrat clair, chaque équipe réinvente ses propres règles.
- Je fixe la responsabilité métier au bon endroit : les validations simples côté interface, la logique métier dans la couche applicative, la persistance dans la couche données.
- Je sépare les zones réseau : exposition publique pour l’interface si nécessaire, réseau privé pour l’application, accès encore plus restreint pour la base.
- Je verrouille les accès : comptes de service distincts, droits minimaux, secrets stockés dans un coffre, rotation planifiée des identifiants.
- Je mesure ce qui se passe : journaux corrélés, métriques de latence, traces distribuées si plusieurs services interviennent.
- Je teste les frontières : tests unitaires pour la logique, tests d’intégration pour les échanges, scénarios de sécurité pour vérifier qu’un composant ne fait pas ce qu’il ne devrait pas faire.
Sur un existant, je procède par étapes. Je ne réécris pas tout d’un coup. J’extrais d’abord les règles métier les plus critiques, je sécurise ensuite les accès aux données, puis je durcis le réseau et les permissions. C’est plus lent sur le papier, mais beaucoup plus fiable en pratique. Et c’est ce pragmatisme qui compte quand on veut faire durer l’architecture.
Ce que je recommande pour une application métier en 2026
Pour une application métier moderne, je recommande une séparation stricte des responsabilités, puis une séparation physique des zones de confiance seulement là où le risque le justifie. En 2026, le bon réflexe n’est pas de multiplier les couches pour faire moderne, mais de garder un schéma simple, testable et durci. Si la charge, les équipes ou le niveau de criticité augmentent, on fait évoluer le modèle sans casser son socle.
- Commencer simple si l’équipe est petite, mais documenter les frontières dès le départ.
- Investir tôt dans l’authentification, le moindre privilège et l’observabilité.
- Éviter de transformer la couche de présentation en mini back-end caché.
- Revoir l’architecture à chaque changement de charge, d’équipe ou d’exposition métier.
À mes yeux, c’est cette discipline qui transforme une architecture théorique en base réellement exploitable sur plusieurs années, sans sacrifier ni la sécurité ni la capacité à livrer.