
Choisir une solution de stockage de données ne consiste pas seulement à acheter plus d’espace. Il faut aussi arbitrer entre performance, sécurité, restauration, conformité et coût d’exploitation, surtout quand les fichiers métiers, les bases applicatives et les sauvegardes n’ont pas les mêmes exigences. Cet article passe en revue les principales technologies, les critères de décision et les réflexes cyber qui évitent les erreurs les plus coûteuses.
Les décisions qui comptent vraiment avant de choisir un stockage
- Le stockage de production, la sauvegarde et l’archivage répondent à trois besoins différents.
- NAS, SAN, stockage objet, cloud et architecture hybride ne servent pas les mêmes usages.
- En cybersécurité, une copie hors site, une copie hors ligne et des tests de restauration changent tout.
- Le chiffrement, la gestion des clés et les droits d’accès sont aussi importants que la capacité.
- Pour les données sensibles, je regarde en priorité les garanties contractuelles, la localisation et le niveau de confiance du fournisseur.
- Le bon choix se fait à partir du RPO, du RTO, du volume, de la sensibilité et du budget total sur plusieurs années.
Stockage, sauvegarde et archivage ne jouent pas le même rôle
Je vois souvent des projets échouer pour une raison simple : on mélange trois besoins qui n’ont rien à voir. Le stockage de production sert à travailler au quotidien, la sauvegarde sert à revenir en arrière après un incident, et l’archivage sert à conserver longtemps des données qui ne sont plus actives, parfois pour des raisons légales ou probatoires.
| Besoin | Objectif | Ce qu’on attend | Ce qui pose problème si on se trompe |
|---|---|---|---|
| Stockage de production | Faire tourner les applications et partager les fichiers | Faible latence, disponibilité, accès rapide | Ralentissements, interruptions, données corrompues |
| Sauvegarde | Restaurer après suppression, panne ou rançongiciel | Copies isolées, testées, récupérables | Impossible de revenir en arrière au pire moment |
| Archivage | Conserver sur la durée, souvent sans modification | Durée de rétention, traçabilité, intégrité | Coût inutile, mauvaise conformité, accès trop lent |
Le point clé, c’est que la restauration n’a pas la même logique selon le besoin. Une base métier critique demande un retour rapide, parfois en minutes ou en heures, alors qu’un archivage peut accepter un délai plus long si l’intégrité et la traçabilité sont garanties. En pratique, je commence toujours par classer les données, puis je rattache chaque classe à son niveau de service attendu. Une fois ce trio distingué, le choix des technologies devient beaucoup plus clair.
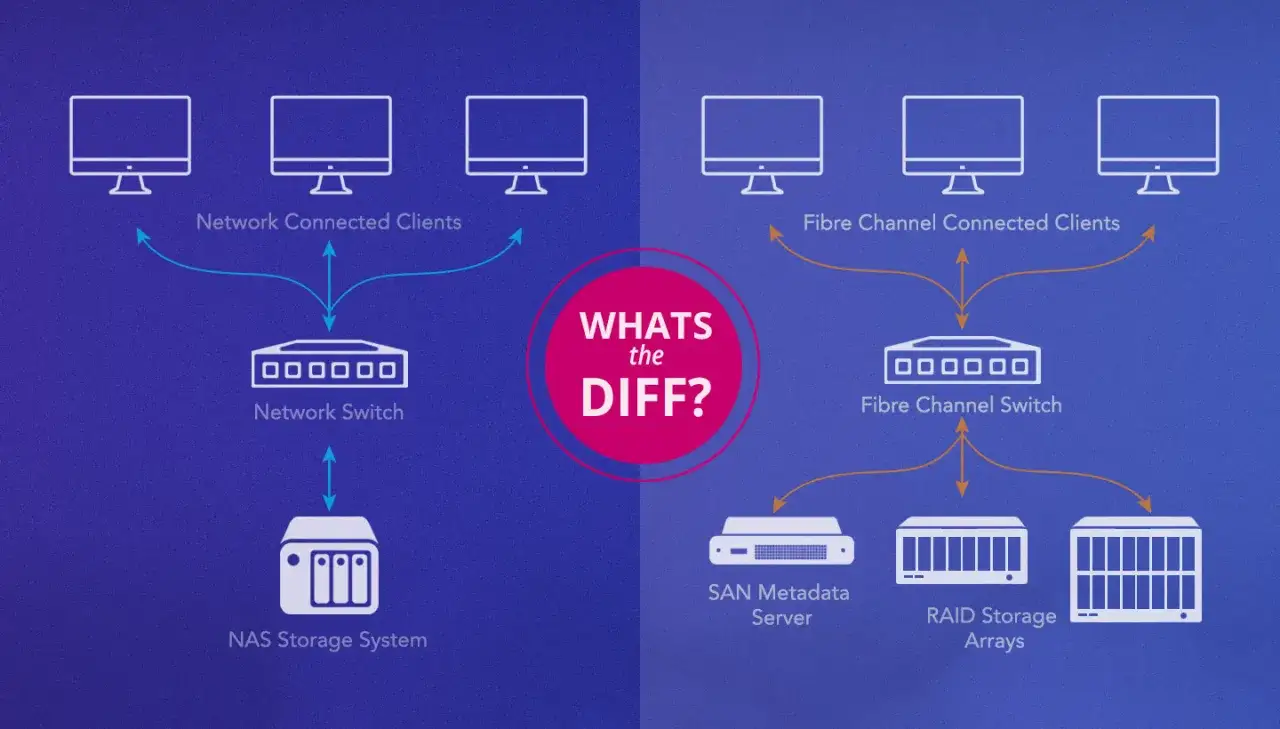
Comparer les familles de technologies sans mélanger les usages
Le marché est plus lisible qu’il n’y paraît si l’on regarde les usages réels. Le stockage local, le NAS, le SAN, le stockage objet et le cloud managé ne s’opposent pas frontalement : chacun répond à un type de charge et à un niveau de maturité différent.
| Technologie | Usage idéal | Atouts | Limites | Mon avis d’usage |
|---|---|---|---|---|
| Stockage local ou DAS | Serveur isolé, petit environnement, test, usage ponctuel | Simplicité, coût initial bas, faible latence | Peu partageable, peu résilient, difficile à faire évoluer | Bien pour du simple, pas pour un socle d’entreprise |
| NAS | Fichiers partagés, collaboration, dossiers métier | Administration simple, accès réseau, bon rapport coût/usage | Peut devenir un point unique si mal redondé | Souvent le meilleur point d’entrée pour une PME |
| SAN | VM, bases de données, charges sensibles à la performance | Débit élevé, faible latence, architecture robuste | Plus complexe, plus chère, nécessite une vraie exploitation | Très pertinent pour les environnements critiques |
| Stockage objet | Archives, logs, sauvegardes, gros volumes non structurés | Scalabilité, durabilité, bon choix pour l’industrialisation | Moins adapté aux accès fichiers classiques et aux petits blocs | Excellent pour les données froides et les sauvegardes immuables |
| Cloud de stockage | Équipes distribuées, élasticité, externalisation, PRA | Souplesse, paiement à l’usage, réplication géographique | Dépendance fournisseur, coût des sorties, gouvernance à cadrer | Très utile si la sécurité et les clés sont bien maîtrisées |
| Architecture hybride | Combinaison local + cloud + sauvegarde externalisée | Bon équilibre entre contrôle, coût et résilience | Demande une vraie gouvernance technique et contractuelle | Souvent le meilleur compromis en entreprise |
Dans les services, le stockage objet et le backup as a service montent vite en pertinence parce qu’ils simplifient l’exploitation et l’extension de capacité. Mais ils ne dispensent pas d’un cadrage sérieux sur les droits d’accès, la rétention, l’export des données et les délais de restauration. Pour des fichiers de travail courants, un NAS bien dimensionné suffit souvent; pour des machines virtuelles ou des bases transactionnelles, le SAN ou une infrastructure hyperconvergée garde de l’intérêt. Le choix n’est pas une question de mode, c’est une question de charge et de responsabilité. Mais la vraie solidité d’une architecture se joue ensuite dans la sauvegarde et la résilience.
La cybersécurité change complètement le cahier des charges
Une solution de stockage utile mais vulnérable ne vaut pas grand-chose. Les attaques par rançongiciel ciblent de plus en plus les sauvegardes elles-mêmes, ce qui oblige à penser isolation, chiffrement, journalisation et restauration testée comme un ensemble cohérent, pas comme des options séparées.
Selon la CNIL, il faut effectuer des sauvegardes fréquentes, en conserver au moins une sur un site géographiquement distinct et en isoler au moins une hors ligne, déconnectée du réseau de l’entreprise. C’est une base très solide, et je la considère comme non négociable dès qu’il y a un enjeu métier réel.
- Copie hors site : elle protège contre l’incendie, l’inondation ou l’indisponibilité d’un site.
- Copie hors ligne : elle réduit le risque qu’un attaquant chiffre aussi les sauvegardes.
- Chiffrement en transit et au repos : il protège les données pendant le transfert et au stockage.
- Gestion séparée des clés : elle évite de confier au fournisseur plus d’accès que nécessaire.
- Authentification forte : elle limite la prise de contrôle via un compte compromis.
- Journalisation : elle permet de comprendre ce qui a été modifié, quand et par qui.
- Tests de restauration : ils prouvent qu’une sauvegarde fonctionne vraiment.
Je rappelle aussi un point souvent sous-estimé : le RAID n’est pas une sauvegarde. Le RAID protège contre une panne disque, pas contre la suppression accidentelle, le chiffrement malveillant ou la mauvaise configuration. Même logique pour les snapshots : ils sont utiles, parfois très utiles, mais ils ne remplacent pas une vraie politique de sauvegarde si l’attaquant peut les supprimer avec les mêmes droits. Avec cette base cyber, le cloud peut être jugé sur ses vrais mérites, pas sur ses promesses marketing.
Le cloud a du sens, mais pas dans tous les cas
Le cloud est souvent présenté comme la réponse la plus flexible. C’est vrai pour beaucoup de cas, surtout quand il faut absorber une croissance rapide, distribuer des fichiers à plusieurs sites ou mettre en place un plan de reprise sans construire tout un site secondaire. Mais le cloud n’efface ni les contraintes de sécurité, ni les coûts de sortie, ni les problèmes de gouvernance.
L’ANSSI met en avant SecNumCloud comme repère de confiance pour certains services cloud sensibles. En pratique, je m’en sers comme d’un filtre de décision quand les données sont sensibles, que le cadre juridique compte autant que la technique, ou que je veux réduire le risque lié aux accès non maîtrisés et aux dépendances contractuelles.
Je regarde généralement cinq questions avant de valider un cloud de stockage :
- Qui contrôle les clés de chiffrement ?
- Où sont hébergées les données et les métadonnées ?
- Quelles sont les conditions de restitution ou de sortie ?
- Les accès administrateurs sont-ils séparés, tracés et limités ?
- Le service reste-t-il exploitable si un compte ou une région cloud tombe ?
Le cloud public fonctionne très bien pour des données non sensibles, des partages collaboratifs, des archives, des sauvegardes externalisées ou des environnements à forte variabilité. Il devient plus délicat quand il faut maîtriser strictement la souveraineté, les droits d’accès, l’extensibilité des clés ou les coûts de rapatriement. Dans ce cas, le chiffrement côté client, les politiques d’accès minimales et une stratégie d’export testée font la différence. Le bon modèle dépend alors moins de la technologie que du profil opérationnel de l’organisation.
Une architecture solide dépend surtout de votre profil d’exploitation
Je ne recommande pas la même architecture à une PME de cinquante personnes, à une ETI multi-sites ou à une structure soumise à des contraintes fortes de conformité. Le bon design part des usages, pas de la fiche technique.
| Profil | Architecture qui marche souvent | Pourquoi |
|---|---|---|
| PME avec fichiers métiers classiques | NAS redondé + sauvegarde cloud ou objet + copie hors site | Simple à administrer, suffisant pour la collaboration, bon compromis de coût |
| ETI ou environnement multi-sites | SAN ou hyperconvergence pour la production + stockage objet pour les archives + sauvegarde immuable | Bon niveau de performance, meilleure séparation des rôles, restauration plus robuste |
| Organisation sensible ou régulée | Segmentation stricte, clés sous contrôle client, comptes séparés, cloud de confiance ou privé bien gouverné | Réduit l’exposition juridique et limite les effets d’un incident de sécurité |
Le terme hyperconvergence désigne une architecture qui rapproche calcul et stockage dans un même ensemble piloté comme un bloc unique. C’est utile quand on veut simplifier l’administration sans sacrifier la montée en charge, mais ce n’est pas toujours le choix le moins cher ni le plus transparent à opérer. De la même manière, le stockage objet est excellent pour les volumes et les archives, mais il n’est pas conçu pour remplacer un partage de fichiers traditionnel avec verrouillage fin et accès applicatif classique.
Dans les faits, une petite structure gagne souvent à partir sur un NAS de qualité, des sauvegardes externalisées et un plan de restauration testé. Une organisation plus grande a intérêt à séparer les couches : production, sauvegarde, archive et reprise d’activité. Cette séparation apporte de la clarté et réduit le rayon d’impact d’un incident. Ces architectures tiennent seulement si l’exploitation évite quelques erreurs très classiques.
Les erreurs qui coûtent cher en production
Les incidents que je rencontre le plus souvent ne viennent pas d’une technologie mal choisie, mais d’un mauvais usage de la bonne technologie. Les erreurs suivantes reviennent en boucle.
- Confondre RAID et sauvegarde : le premier protège une disponibilité locale, pas une perte logique ou un rançongiciel.
- Conserver les sauvegardes dans le même domaine d’administration : si le compte principal tombe, tout tombe avec lui.
- Laisser les paramètres cloud par défaut : un conteneur ou un espace de stockage mal exposé suffit à créer une fuite.
- Ne jamais tester la restauration : une sauvegarde non restaurée reste une promesse, pas une preuve.
- Ignorer la rétention : trop courte, elle casse la conformité; trop longue, elle fait exploser les coûts.
- Sous-estimer les temps de rapatriement : restaurer plusieurs téraoctets peut prendre bien plus longtemps que prévu.
- Oublier les métadonnées et les droits : on croit avoir déplacé les données, mais on a laissé les accès ouverts.
- Ne pas documenter le mode dégradé : le jour de l’incident, personne ne sait qui fait quoi.
La plupart de ces erreurs sont évitables avec une discipline simple : classification des données, séparation des comptes, politiques de rétention, tests réguliers et documentation claire. Ce n’est pas spectaculaire, mais c’est ce qui fait tenir une architecture dans la durée. La dernière étape consiste donc à passer du principe à une grille de décision concrète.
Avant de signer, je vérifierais ces cinq points
Si je devais choisir aujourd’hui une solution de stockage pour une organisation française, je partirais d’une grille très simple. Elle évite les achats trop rapides et les promesses floues.
- Quelle donnée protège-t-on exactement ? Je classe d’abord les données selon leur sensibilité, leur valeur métier et leur durée de conservation.
- Quel RPO et quel RTO sont réellement acceptables ? Le RPO indique la perte de données maximale tolérable; le RTO indique le temps maximal d’interruption acceptable.
- Où se trouve la copie de secours ? Je veux au moins une copie hors site, idéalement une copie hors ligne ou immuable.
- Qui détient les clés et les droits d’administration ? Si le fournisseur voit tout, il faut que ce soit assumé contractuellement et techniquement.
- Combien coûtera le cycle complet sur 3 ans ? J’inclus le stockage, le logiciel, les sorties de données, l’exploitation, le support et les tests de restauration.
Au fond, la meilleure architecture n’est pas la plus sophistiquée; c’est celle qu’on sait restaurer, contrôler et faire évoluer sans surprise. Pour des fichiers métiers courants, je privilégie souvent un NAS solide avec sauvegarde externalisée et copie isolée. Pour des charges critiques, je préfère séparer production, sauvegarde et reprise. Et pour les données sensibles, je fais primer le niveau de confiance, la maîtrise des clés et la capacité à reprendre la main vite, sans improvisation.