
Dans une organisation AWS, le sujet n’est pas seulement de « créer des comptes », mais de construire un cadre qui limite les risques, clarifie les responsabilités et facilite les audits. Une landing zone AWS répond à ce besoin en posant une base multi-comptes avec identité centralisée, journalisation, contrôles de sécurité et gouvernance cohérente. Je vais ici aller au-delà de la définition pour montrer ce que cela change concrètement, comment la mettre en place et où se trouvent les vrais pièges en cybersécurité.
Les points à garder en tête avant de construire votre base AWS
- Une base multi-comptes sert d’abord à isoler les risques et à rendre la gouvernance plus lisible.
- Les fondations utiles sont toujours les mêmes: identité, journaux, contrôle d’accès, séparation des environnements et supervision.
- AWS Control Tower accélère la mise en place, mais il ne remplace ni la conception d’architecture ni la discipline opérationnelle.
- Depuis la version 4.0, la structure est plus flexible et certaines intégrations de service peuvent être activées de façon sélective.
- Le service lui-même n’a pas de surcoût direct, mais les services qu’il active peuvent faire monter la facture.
Ce qu’une landing zone apporte vraiment à une organisation AWS
Quand je parle de base multi-comptes, je ne parle pas d’un simple découpage administratif. L’idée est de créer un environnement où les charges de travail, les logs, les fonctions d’audit et les privilèges sensibles ne vivent pas tous au même endroit. C’est cette séparation qui change le niveau de risque, surtout dans les organisations qui veulent éviter qu’une erreur de configuration ou qu’un compte compromis fasse tomber l’ensemble du périmètre.Selon AWS, une landing zone est un environnement multi-comptes bien architecturé, fondé sur les bonnes pratiques de sécurité et de conformité. En pratique, cela signifie qu’on prépare avant tout le déploiement des applications, pas après coup. Je trouve que c’est une nuance importante: trop d’équipes construisent d’abord les workloads et corrigent ensuite la gouvernance, alors que le bon ordre est l’inverse.
Pour une DSI française, l’intérêt est très concret. On gagne une meilleure séparation des responsabilités, une traçabilité plus propre pour les audits internes, et une base plus crédible pour les exigences liées au RGPD, aux contrôles de sécurité ou à la segmentation des environnements. Ce cadre ne résout pas tout, mais il évite de partir avec une dette de gouvernance dès le premier jour. C’est justement ce socle qui permet ensuite de choisir les bonnes briques de sécurité.
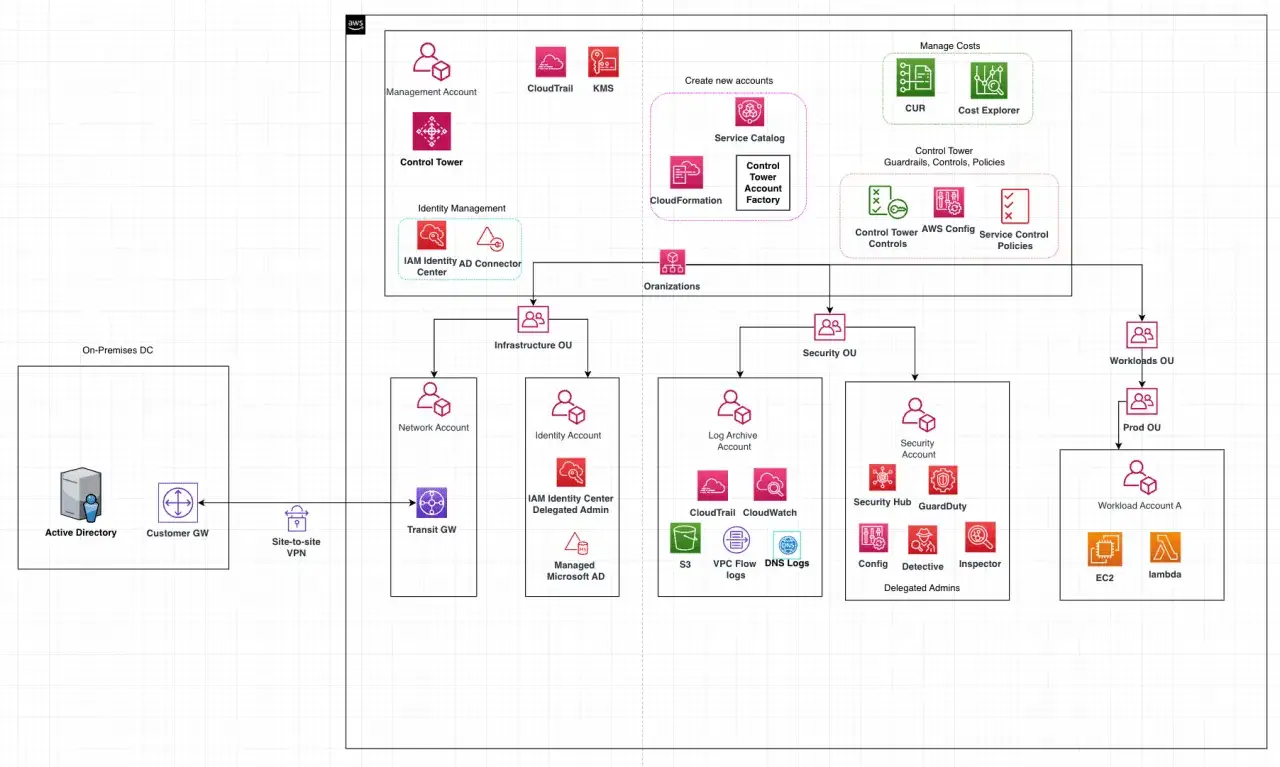
Les briques de sécurité à prévoir dès le départ
Quand on veut un environnement réellement exploitable, il faut penser la sécurité comme un système et pas comme une couche ajoutée à la fin. Je commence toujours par les mêmes fondations: identité, comptes, logs, réseau et règles de contrôle. Si l’une de ces briques manque, le modèle reste fragile.
Les comptes à isoler
La première règle consiste à ne pas tout faire vivre dans le même compte. Une base saine repose généralement sur un compte d’administration, un compte de centralisation des journaux, un compte d’audit et des comptes dédiés aux workloads. AWS Control Tower crée d’ailleurs deux comptes partagés lors de la mise en place initiale: un compte d’archive des journaux et un compte d’audit.| Type de compte | Rôle principal | Pourquoi c’est utile |
|---|---|---|
| Compte de management | Administration de l’organisation et facturation | On limite son usage pour réduire l’impact d’une mauvaise manipulation |
| Compte d’archive des journaux | Stockage centralisé des logs | On protège la preuve et la traçabilité en cas d’incident |
| Compte d’audit ou sécurité | Lecture, supervision et contrôle | On sépare le regard de sécurité des équipes qui exploitent les workloads |
| Comptes applicatifs | Développement, préproduction, production | On évite qu’un incident de test contamine la production |
| Compte sandbox | Expérimentation encadrée | On permet l’innovation sans ouvrir le cœur du SI |
Identité et droits d’accès
Je privilégie une logique de moindre privilège dès le départ. Dans AWS, cela passe par IAM Identity Center pour l’accès fédéré, des rôles courts et ciblés, et des comptes séparés pour les usages sensibles. Le vrai sujet n’est pas seulement « qui a accès », mais jusqu’où cet accès peut aller si un identifiant est compromis.Il faut aussi prévoir un mécanisme de secours, souvent appelé compte ou rôle de rupture de glace, pour ne pas dépendre d’un seul chemin d’administration. Dans les organisations matures, ce point est testé régulièrement, parce qu’un accès de secours non vérifié est un faux sentiment de sécurité.
Journaux et détection
La journalisation n’est pas une option. CloudTrail, AWS Config et les flux d’alerte doivent être conçus pour résister aux changements de comptes et d’équipes. Le principe est simple: les journaux doivent être centralisés, difficiles à altérer et exploitables rapidement en cas d’incident.
J’insiste aussi sur la conservation. Un journal qui n’est pas consultable sur la durée perd une grande partie de sa valeur. Les équipes sécurité gagnent à définir dès le départ la durée de rétention, les accès en lecture et les règles d’archivage.
Lire aussi : RGPD et IA - Évitez les erreurs coûteuses, sécurisez vos projets
Réseau et sorties vers l’extérieur
Beaucoup de projets ratent leur base multi-comptes parce qu’ils sous-estiment le réseau. Il faut réfléchir à la segmentation, aux points de sortie internet, aux endpoints privés et aux services partagés. Si le trafic sort partout de manière libre, la séparation des comptes reste théorique.
Dans une logique d’entreprise, je préfère souvent une architecture où les accès sortants sont centralisés et surveillés, avec des VPC endpoints pour réduire l’exposition. Une fois ces fondations posées, la vraie question devient celle du déploiement concret.
Comment la mettre en place avec AWS Control Tower
Pour la plupart des équipes, AWS Control Tower est le point d’entrée le plus rationnel. Le service orchestre AWS Organizations, IAM Identity Center, Service Catalog et les mécanismes de gouvernance de base pour démarrer plus vite qu’une construction entièrement manuelle. Depuis la version 4.0, il est aussi plus souple: certaines intégrations sont optionnelles, et la structure d’organisation n’est plus aussi rigide qu’avant.
Je résume la démarche en six étapes simples, mais chacune mérite d’être préparée sérieusement.
- Préparer l’organisation existante ou nouvelle en vérifiant les quotas, les comptes disponibles et les adresses e-mail dédiées aux comptes partagés.
- Choisir la région d’accueil et valider qu’elle correspond bien aux besoins opérationnels, de conformité et de latence.
- Lancer la landing zone avec les services de gouvernance requis, puis vérifier que les comptes de journalisation et d’audit sont créés correctement.
- Définir la structure des OUs selon les usages réels de l’entreprise, sans calquer artificiellement une vieille structure d’équipe.
- Enrôler les comptes existants dans les bonnes unités organisationnelles pour leur appliquer les contrôles attendus.
- Contrôler le drift et automatiser les mises à jour, car une base non maintenue finit toujours par s’écarter du modèle prévu.
La version actuelle permet aussi un mode axé uniquement sur les contrôles pour les organisations qui ont déjà une structure AWS bien en place. C’est une option intéressante si vous ne voulez pas reconstruire tout le socle, mais elle n’est pas magique: elle fonctionne mieux quand les règles d’organisation sont déjà propres et documentées.
Mon conseil est simple: si vous partez de zéro, visez une base standardisée. Si vous avez déjà une organisation AWS ancienne, traitez le sujet comme un chantier de gouvernance progressive, pas comme une migration « clic et c’est terminé ». C’est à ce moment-là qu’il devient utile de comparer l’approche managée et le sur-mesure.
Choisir entre Control Tower et une base sur mesure
Il existe deux grandes approches: utiliser le cadre proposé par AWS ou construire un modèle entièrement personnalisé. Les deux sont valables, mais elles ne répondent pas aux mêmes contraintes. J’observe souvent que les entreprises surestiment leur capacité à maintenir du sur-mesure dans la durée, alors qu’elles ont surtout besoin d’un standard robuste.
| Critère | AWS Control Tower | Base sur mesure |
|---|---|---|
| Vitesse de démarrage | Élevée | Plus lente |
| Niveau d’effort initial | Modéré | Fort |
| Flexibilité | Bonne, surtout depuis la version 4.0 | Maximale |
| Charge opérationnelle | Plus faible au départ | Plus élevée, car il faut tout maintenir |
| Cas d’usage idéal | Entreprise qui veut une gouvernance rapide et un cadre éprouvé | Organisation avec contraintes très spécifiques ou forte maturité AWS |
| Risque principal | Penser que l’outil suffit sans travail d’architecture | Créer une solution complexe difficile à faire vivre |
En pratique, je recommande Control Tower à toutes les équipes qui veulent réduire le délai de mise en sécurité et standardiser les comptes sans réinventer le modèle. Le sur-mesure ne se justifie que si vous avez de vraies contraintes de conformité, d’intégration ou d’automatisation que le cadre standard ne couvre pas assez bien. Cette comparaison mène directement aux erreurs les plus fréquentes, celles qui fragilisent la base même quand l’outil est bien choisi.
Les erreurs qui fragilisent le modèle multi-comptes
Les incidents que je vois le plus souvent ne viennent pas d’une faiblesse théorique du service, mais d’un mauvais usage du cadre. Voici les erreurs qui reviennent régulièrement, et que je conseille de traiter dès la phase de conception.
- Tout concentrer dans un seul compte au nom de la simplicité. On gagne en vitesse, on perd en isolation et en capacité de remédiation.
- Confondre compte d’administration et compte de production. Le compte de management doit rester aussi propre que possible.
- Modifier manuellement les garde-fous sans passer par le modèle de gouvernance. Le drift devient alors presque inévitable.
- Oublier les comptes existants déjà présents dans l’organisation. Une nouvelle base ne gouverne pas automatiquement le passé.
- Sous-estimer l’effet des ressources éphémères sur la journalisation et les coûts, surtout dans les environnements de test et de CI/CD.
- Penser que l’OU suffit à elle seule. Une unité organisationnelle structure la gouvernance, mais elle ne remplace ni les contrôles ni la discipline d’exploitation.
Le point le plus trompeur est souvent le drift. Quand les équipes modifient l’organisation en dehors du cadre prévu, la gouvernance peut sembler intacte visuellement alors qu’elle a déjà perdu une partie de sa cohérence. Si l’on ne les surveille pas, ces écarts se transforment vite en dette technique et en dette de sécurité.
Ce que je surveille après le déploiement pour garder une base saine
Une bonne mise en place ne suffit pas. La différence entre une architecture solide et une architecture réellement durable se joue dans l’exploitation. Je surveille en priorité quatre choses: les coûts, la dérive de configuration, les droits d’accès et la capacité à absorber de nouveaux comptes sans casser le modèle.
AWS indique qu’il n’y a pas de frais supplémentaires pour utiliser Control Tower lui-même. En revanche, dès que la base active des services comme AWS Config, CloudTrail, Amazon S3, Amazon CloudWatch, SNS, Service Catalog ou Amazon VPC, la facture devient dépendante de l’usage. AWS Config est particulièrement sensible, car il facture les configuration items générés, et les environnements à ressources éphémères peuvent faire grimper le volume très vite.
| Poste de coût | Ce qui le fait monter | Ce que je recommande |
|---|---|---|
| AWS Config | Nombre de ressources, régions et changements | Limiter les régions non nécessaires et surveiller les workloads temporaires |
| CloudTrail | Volume d’événements et rétention | Définir une politique d’archivage claire et tester la recherche des logs |
| S3 | Stockage des journaux et durée de conservation | Optimiser la rétention et appliquer des règles de cycle de vie |
| CloudWatch et SNS | Alertes, métriques et notifications | Limiter le bruit d’alerte et garder des seuils utiles |
| VPC et réseau | NAT Gateway, trafic sortant, endpoints | Mesurer l’usage avant de généraliser les sorties centralisées |
Je conseille aussi de traiter la mise à jour de la base comme un processus normal, pas comme une opération exceptionnelle. La version 4.0 a renforcé la souplesse du modèle, mais cette souplesse ne dispense pas de suivre les évolutions, de corriger les écarts et de documenter les exceptions. Dans un environnement multi-comptes, la gouvernance n’est jamais un état final, c’est un travail continu.
La bonne approche consiste donc à partir d’un socle simple, à centraliser ce qui doit l’être, et à laisser aux équipes métiers l’autonomie dont elles ont réellement besoin. Si je devais résumer la logique en une phrase, je dirais qu’une base AWS bien conçue ne cherche pas à tout contrôler, mais à rendre chaque contrôle utile, visible et maintenable dans le temps.