
Construire un bon pipeline de données ne consiste pas seulement à déplacer des lignes d’un système à un autre. Il faut aussi garder la main sur l’hébergement, les secrets, les droits d’accès, les logs et la maintenance, sinon la chaîne de données finit par coûter plus cher qu’elle ne rapporte. C’est précisément là qu’une solution ETL open source peut devenir un vrai levier, à condition de choisir un outil adapté au volume, au niveau de contrôle attendu et à la maturité de l’équipe.
Je vais donc aller à l’essentiel: ce que recouvre réellement ce type d’outil, les plateformes qui comptent encore en 2026, et la manière de trancher sans se tromper entre ingestion, orchestration, transformation et sécurité. L’idée est de vous aider à faire un choix utile, pas seulement “techniquement séduisant”.
Les points à garder en tête avant de comparer les outils
- Le meilleur choix dépend d’abord du type de flux: batch, quasi temps réel, ou flux sensibles à forte traçabilité.
- Airbyte et Meltano sont solides pour centraliser rapidement des données SaaS, bases et fichiers.
- Apache NiFi et Apache Hop prennent l’avantage quand la visualisation, le routage ou la provenance des données deviennent critiques.
- Une bibliothèque Python comme dlt convient bien aux équipes qui préfèrent coder leurs pipelines plutôt que les manipuler dans une interface.
- La sécurité, la gestion des secrets et la capacité à exploiter la plateforme comptent autant que le catalogue de connecteurs.
Ce que recouvre vraiment un ETL open source
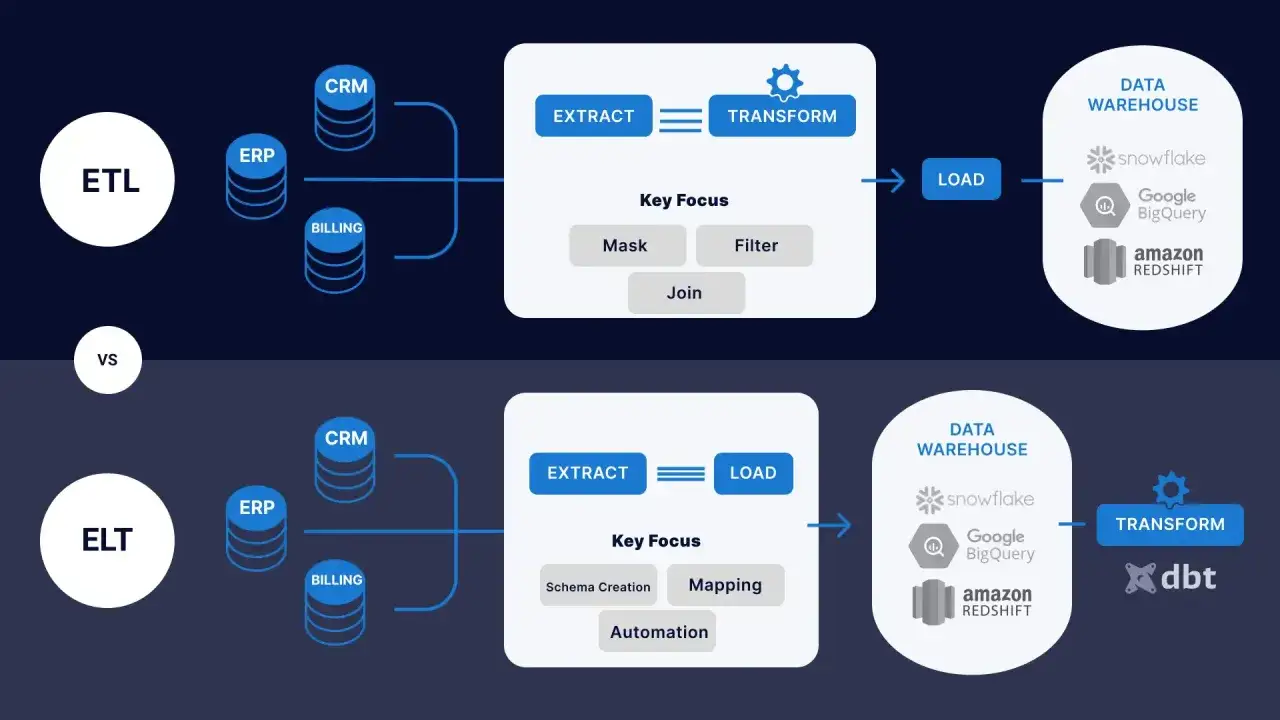
À la base, ETL signifie Extract, Transform, Load: extraire les données, les transformer, puis les charger dans une cible exploitable. En pratique, beaucoup d’équipes travaillent désormais en ELT ou en dataflow hybride, parce que les transformations lourdes sont souvent plus simples à gérer dans l’entrepôt de données ou dans un moteur dédié. Le terme reste utile, mais il ne faut pas le lire trop littéralement.
Ce qui compte, dans une approche libre, ce n’est pas seulement l’absence de licence payante. C’est la capacité à déployer chez soi, tracer ce qui circule, contrôler les accès et réverser proprement si le besoin change. Pour une DSI ou une équipe cybersécurité, c’est un point décisif: un outil d’intégration n’est jamais neutre, il devient vite une pièce de l’architecture de confiance.
Je distingue donc toujours trois familles: les plateformes d’ingestion, les moteurs de dataflow et les outils code-first. Cette distinction paraît théorique au départ, mais elle évite beaucoup d’erreurs de sélection lorsque l’on passe à l’exploitation réelle.
Les outils qui comptent vraiment en 2026
Le marché s’est clarifié. On voit moins de suites monolithiques et davantage de briques spécialisées, avec chacune un terrain de jeu très net. Voici la lecture que j’en fais aujourd’hui.
| Outil | Positionnement | Ce qu’il fait bien | Limites à connaître | Quand je le retiens |
|---|---|---|---|---|
| Airbyte | Plateforme d’ingestion et de réplication | Beaucoup de connecteurs, déploiement self-hosted ou cloud, intégration API et automatisation avancée | Les transformations métier complexes sont souvent mieux gérées ailleurs | Quand il faut centraliser vite des sources SaaS, des bases de données et des fichiers |
| Apache NiFi | Dataflow visuel orienté routage et médiation | Interface web, faible latence, excellente traçabilité, provenance fine des données | Peut devenir lourd si on y concentre trop de logique métier | Quand la supervision, le routage et l’audit priment sur la pure volumétrie |
| Meltano | Socle DataOps self-hosted, code-first | Approche très compatible avec Git, CI/CD et culture DevOps, plus de 600 connecteurs annoncés | Demande plus de discipline d’exploitation qu’une interface “clic and run” | Quand l’équipe veut versionner ses pipelines comme du logiciel |
| Apache Hop | Plateforme d’intégration et d’orchestration visuelle | Architecture metadata-driven, workflows et pipelines, exécution sur plusieurs moteurs, dont Spark et Flink | Nécessite Java 17 et une exploitation plus structurée | Quand on cherche une alternative moderne à une culture ETL graphique |
| dlt | Bibliothèque Python d’extraction et de chargement | Très légère, schémas déduits, incrémental, adaptée aux équipes qui codent déjà | Ce n’est pas une suite visuelle complète | Quand les pipelines doivent vivre dans le code et évoluer vite |
Deux points méritent une précision. D’abord, Talend Open Studio a été discontinué au 31 janvier 2024; en 2026, je ne le considère donc plus comme une base sérieuse pour lancer un nouveau projet. Ensuite, même dans les outils encore actifs, le nombre de connecteurs ne dit pas tout: ce qui compte, c’est leur maturité, leur fréquence de mise à jour et la facilité à les opérer dans votre contexte.
Avec ce tableau en tête, le vrai travail consiste maintenant à faire correspondre l’outil au besoin réel, pas au réflexe de la communauté.
Comment je choisis selon le contexte réel
Je ne commence jamais par demander “quel est le meilleur outil”. Je commence par regarder le rythme des données, le niveau de contrôle attendu et le profil de l’équipe. C’est beaucoup plus fiable qu’un comparatif générique.
Pour l’ingestion rapide de sources SaaS
Si votre besoin principal est de faire remonter rapidement des données depuis des applications métier, des bases ou des fichiers vers un entrepôt, je regarde d’abord Airbyte. C’est souvent le chemin le plus direct quand il faut produire une première chaîne utile en peu de temps. Meltano devient pertinent si la gouvernance de l’équipe passe par Git, les revues de code et une logique d’automatisation proche du développement logiciel.Pour les flux sensibles et la traçabilité
Dès que l’on touche à des flux opérationnels, de la télémétrie, des journaux de sécurité ou des échanges entre systèmes critiques, Apache NiFi prend l’avantage. Sa force n’est pas seulement la visualisation; c’est la capacité à voir comment les données circulent et à retracer chaque étape. En cybersécurité, cette provenance fine change la donne quand il faut comprendre rapidement ce qui a été vu, modifié ou perdu.Pour une équipe Python
Si l’équipe travaille déjà en Python et veut éviter une plateforme trop lourde, dlt est très cohérent. On gagne en vitesse de développement, en lisibilité et en proximité avec le code applicatif. En revanche, il faut accepter d’assembler soi-même ce que certaines suites apportent nativement: orchestration, supervision, alerting et gouvernance.
Pour un héritage ETL visuel
Si vous venez d’un univers Pentaho, de jobs visuels ou de traitements hybrides entre on-prem et cloud, Apache Hop mérite une vraie évaluation. Son approche metadata-driven est propre, et sa capacité à s’exécuter sur différents moteurs intéresse les équipes qui ne veulent pas enfermer leurs flux dans un seul runtime. Je le recommande surtout quand il existe déjà une culture d’exploitation structurée et qu’un peu de complexité supplémentaire reste acceptable.
Au fond, le bon choix dépend moins de la “puissance” affichée que de la manière dont votre équipe va réellement vivre avec l’outil au quotidien.
La sécurité et la conformité doivent guider le design
Dans une entreprise française, je considère la sécurité comme un critère de sélection, pas comme une couche ajoutée après coup. Un outil d’intégration qui fonctionne mais qu’on ne peut ni durcir, ni auditer, ni exploiter proprement devient rapidement un risque opérationnel.
Réduire la surface d’attaque
Je privilégie les déploiements self-hosted quand les données sont sensibles, parce qu’ils donnent plus de contrôle sur le réseau, les dépendances et les journaux. Cela ne veut pas dire “plus sûr par défaut”; cela veut dire “plus maîtrisable”. Il faut alors limiter les connecteurs installés, isoler les environnements et éviter d’exposer inutilement l’interface d’administration.
Gérer les secrets, les droits et les journaux
Le vrai point faible des pipelines, ce sont souvent les identifiants en clair, les comptes de service trop larges et les logs trop bavards. Je recommande systématiquement une gestion centralisée des secrets, des rôles séparés par environnement et une journalisation exploitable en incident response. RBAC, c’est le contrôle d’accès par rôle: un administrateur, un développeur et un analyste ne doivent pas avoir le même périmètre.
Quand l’outil fournit de la provenance ou de l’audit, je m’en sers. La provenance, c’est l’historique précis du passage des données dans le système: qui a reçu quoi, quand, et par quel chemin. Pour un responsable sécurité, c’est souvent plus utile qu’un simple “job succeeded”.
Lire aussi : Blockchain en cybersécurité - Vrai potentiel ou simple buzz ?
Conformité et souveraineté
En France et dans l’Union européenne, la question n’est pas seulement de savoir si l’outil respecte le RGPD. Il faut aussi regarder où les données transitent, combien de copies temporaires sont créées, qui peut lire les traces et ce qui part dans des services tiers. Quand des données personnelles, RH ou clients sont en jeu, je préfère une architecture qui limite la dispersion plutôt qu’une architecture “pratique” mais difficile à expliquer en audit.
La bonne nouvelle, c’est qu’une pile libre bien pensée aide justement à garder ces sujets sous contrôle. À partir de là, il faut surtout éviter les pièges les plus coûteux.
Les erreurs qui reviennent le plus souvent
- Choisir sur le catalogue de connecteurs uniquement: un connecteur disponible n’est pas forcément mature, bien maintenu ou facile à faire évoluer.
- Confondre ingestion et transformation métier: plus on mélange les deux dans le même outil, plus la maintenance devient fragile.
- Oublier l’exploitation: une plateforme sans supervision, sans alerting et sans stratégie de reprise finit par bloquer l’équipe au premier incident.
- Ne pas versionner les pipelines: sans Git, sans revue et sans environnement de test, on transforme vite les flux de données en dette technique invisible.
- Sous-estimer les mises à jour: Java, plugins, connecteurs et dépendances évoluent; si personne n’en assume le suivi, le risque monte vite.
- Ignorer la qualité de données: un pipeline qui charge vite des données fausses ne crée pas de valeur, il industrialise l’erreur.
Le coût caché n’est pas seulement le logiciel lui-même; c’est le temps passé à le faire vivre correctement. C’est pour cette raison que je préfère toujours un périmètre réduit mais propre à une plateforme ambitieuse que personne n’osera toucher.
Une mise en route raisonnable en 30 jours
Quand une équipe veut avancer sans se noyer, je lui conseille un démarrage en quatre semaines, sur un cas d’usage limité. Pas de “big bang”, pas de migration totale dès le départ. Il faut prouver que la chaîne fonctionne, puis seulement l’étendre.
- Semaine 1: choisir une source, une cible et un flux non critique, puis définir trois indicateurs simples: fraîcheur, taux d’échec et temps de reprise.
- Semaine 2: déployer l’instance, isoler les environnements, brancher la gestion des secrets et activer les logs utiles à l’exploitation.
- Semaine 3: construire le pipeline, tester les cas d’échec, vérifier les reprises, et documenter ce qui doit être surveillé en production.
- Semaine 4: mettre le flux sous supervision, mesurer le coût réel d’exploitation, puis décider si l’on industrialise, ajuste ou change d’outil.
Je recommande de garder ce pilote aussi concret que possible. Une seule source mal choisie peut fausser toute l’évaluation, alors qu’un cas d’usage bien ciblé donne une lecture beaucoup plus honnête de la robustesse réelle.
Une fois ce premier cycle terminé, le débat change de nature: on ne parle plus d’un outil “intéressant”, mais d’un composant d’architecture qu’il faut pouvoir défendre face aux métiers, à la sécurité et à la production.
Ce que je recommande pour une équipe IT en France en 2026
Si je devais simplifier au maximum, je dirais ceci: Airbyte pour démarrer vite sur des sources multiples et alimenter un entrepôt; NiFi pour les flux sensibles, traçables ou quasi temps réel; Meltano ou dlt pour les équipes qui veulent rester très proches du code; Apache Hop pour les organisations qui ont besoin d’une approche visuelle sérieuse et d’une transition depuis un héritage ETL plus ancien.Je ne retiens plus Talend Open Studio comme point de départ pour un nouveau projet, et je réserve l’édition gratuite de Pentaho aux besoins de formation ou de prototype non productif. Si votre enjeu principal est la transformation numérique sans dette cachée, le bon arbitrage n’est pas “gratuit contre payant”, mais gouverné contre fragile.
En 2026, la meilleure pile de données n’est pas celle qui promet le plus de connecteurs. C’est celle que votre équipe peut exploiter proprement, sécuriser sans bricolage et faire évoluer sans perdre la trace de ce qui circule.