
La gestion des incidents n’est pas un simple réflexe de support: c’est le mécanisme qui permet de remettre un service sur pied vite, sans brouiller la priorité métier ni multiplier les erreurs de communication. Bien menée, elle réduit le temps d’arrêt, clarifie qui décide et évite de confondre symptôme, cause et demande utilisateur. Dans cet article, je passe en revue le déroulé concret, les règles de priorisation, les outils utiles et les points de vigilance qui font réellement la différence.
Les repères qui permettent de rétablir un service sans improviser
- Un incident correspond à une interruption ou une dégradation de service ; un problème désigne la cause probable ou racine.
- La priorité dépend de l’impact métier et de l’urgence, pas seulement du bruit produit par l’alerte.
- Un bon flux couvre détection, qualification, affectation, contournement, résolution, clôture et retour d’expérience.
- Les outils utiles sont ceux qui accélèrent le tri, la communication et la traçabilité, pas seulement ceux qui ouvrent des tickets.
- Le MTTR, le taux de réouverture et le respect des SLA disent souvent plus sur la maturité qu’un simple volume de tickets traités.
Ce qu’un incident recouvre vraiment et ce qui n’en est pas un
Dans une logique ITSM, un incident est un événement non planifié qui perturbe un service ou en dégrade la qualité. Ce n’est pas forcément une panne totale: une lenteur sévère, une fonctionnalité critique indisponible ou une erreur récurrente peuvent déjà suffire à déclencher une prise en charge. Ce point compte, parce qu’un mauvais cadrage au départ fait perdre du temps à tout le monde.
Je distingue toujours trois objets qui sont trop souvent mélangés dans les équipes:
| Objet | Ce que c’est | Ce que l’équipe cherche à faire |
|---|---|---|
| Incident | Une interruption ou une dégradation visible du service | Rétablir le service normal le plus vite possible |
| Problème | La cause sous-jacente ou potentielle d’un ou plusieurs incidents | Comprendre pourquoi cela se produit et éviter la répétition |
| Demande de service | Une requête standard, attendue et non liée à une panne | Traiter la demande selon un circuit prévisible |
Le piège classique, c’est de traiter une demande comme un incident, ou l’inverse. Dans le premier cas, on sature inutilement l’équipe support et on pollue les SLA. Dans le second, on laisse traîner un service dégradé alors que l’utilisateur attend une action rapide. Une équipe mature sait faire ce tri en amont, avant même d’entrer dans le diagnostic.
Une fois ce tri posé, le vrai enjeu devient la chaîne d’exécution.
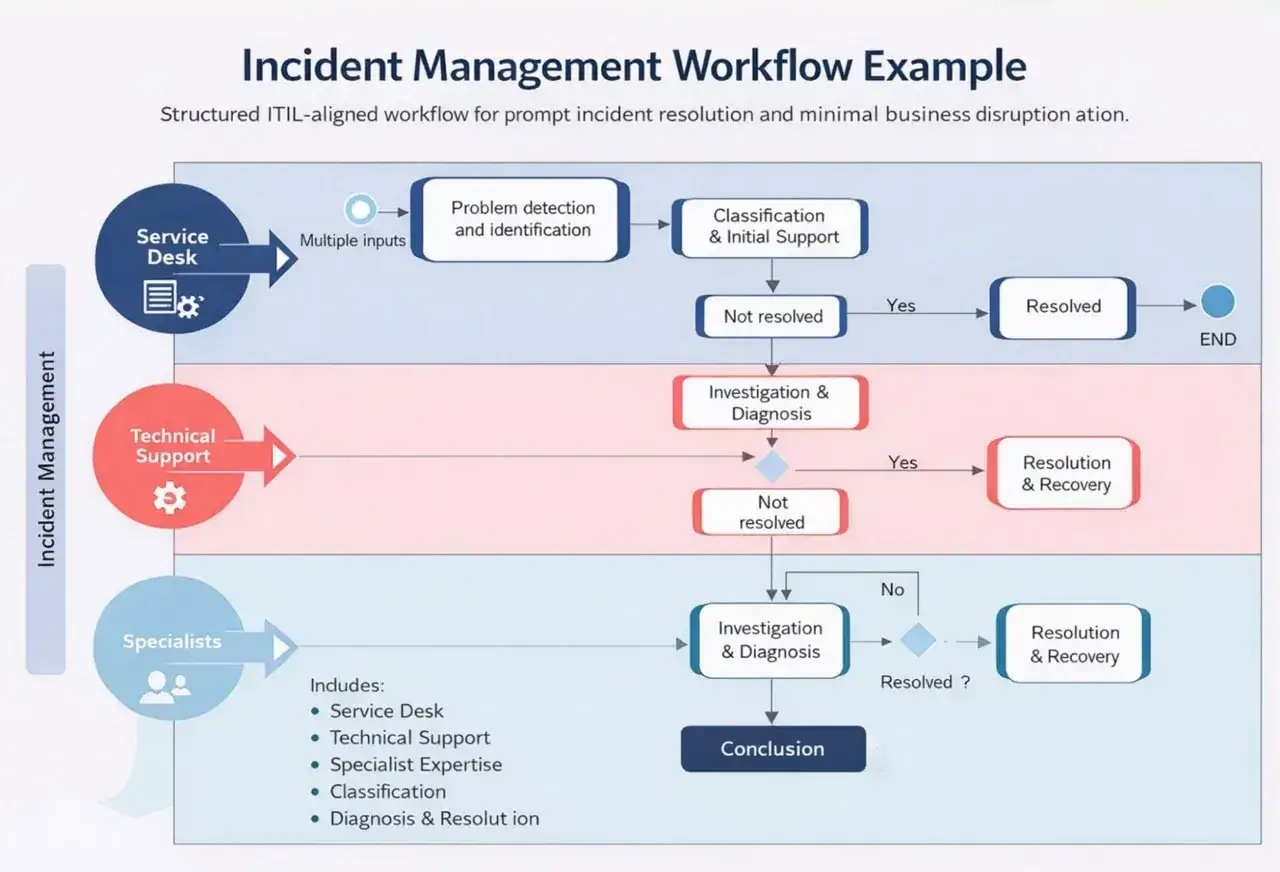
Le déroulé opérationnel d’un incident de bout en bout
Quand le flux est clair, l’équipe évite les débats stériles au mauvais moment. Je préfère une séquence courte, lisible et répétable plutôt qu’un processus trop sophistiqué que personne n’applique sous pression.
- Détection ou signalement - l’incident arrive via supervision, utilisateur, support, astreinte ou canal automatique. Plus la détection est tôt, plus l’impact métier reste contenu.
- Enregistrement - on crée un ticket avec les faits utiles: service concerné, heure d’apparition, messages d’erreur, périmètre affecté, premier niveau de contexte.
- Qualification - on vérifie qu’il s’agit bien d’un incident et non d’une demande standard ou d’un simple bruit de monitoring.
- Priorisation - on évalue l’impact, l’urgence et la portée, puis on fixe un niveau de traitement cohérent.
- Affectation - un propriétaire unique prend la main; c’est lui qui coordonne, arbitre et relance les bons interlocuteurs.
- Diagnostic - l’équipe cherche la cause immédiate, puis un contournement si la résolution définitive prend du temps.
- Restauration - on remet le service en état de fonctionnement normal, même si la cause racine n’est pas encore totalement éliminée.
- Clôture et apprentissage - on documente ce qui a été fait, puis on capitalise dans la base de connaissances ou la revue post-incident.
Le point que je vois le plus souvent négligé, c’est la phase de communication. Un bon traitement d’incident ne se juge pas seulement à la vitesse de résolution, mais aussi à la capacité de tenir les parties prenantes informées avec un rythme crédible et stable. Si les utilisateurs ne savent pas ce qui se passe, ils perçoivent vite l’incident comme plus grave qu’il ne l’est peut-être réellement.
Mais pour agir vite, il faut aussi décider vite de ce qui passe devant quoi.
Prioriser sans se tromper avec impact, urgence et criticité
La priorisation est souvent le point où les équipes perdent le plus de temps. À mon sens, une bonne matrice doit être assez simple pour être utilisée sous stress, mais assez précise pour éviter de tout mettre au même niveau.
Impact, urgence et criticité ne mesurent pas la même chose
L’impact répond à la question « qui est touché, et à quel point ? ». L’urgence répond à « combien de temps peut-on attendre avant d’agir ? ». La criticité, elle, est la synthèse opérationnelle qui permet de décider qui s’en occupe maintenant. Confondre ces notions produit des arbitrages bancals: un incident très visible n’est pas forcément le plus grave, et un incident discret peut avoir des conséquences lourdes sur la conformité ou la sécurité.
Je conseille de garder une grille courte, puis de l’adapter à vos SLA et à votre organisation. Voici une base simple que j’utilise souvent comme repère de départ:
| Niveau | Situation typique | Prise en charge conseillée | Rythme de communication |
|---|---|---|---|
| P1 | Service indisponible pour tous, risque de perte de données ou fonction critique bloquée | Immédiate, sans attente | Toutes les 30 minutes |
| P2 | Partie importante des utilisateurs touchée ou fonctionnalité clé fortement dégradée | Dans les 30 minutes | Toutes les 60 minutes |
| P3 | Impact limité, contournement disponible, activité métier ralentie mais maintenue | Dans la demi-journée | À chaque jalon majeur |
| P4 | Faible impact, pas d’arrêt de production, correction planifiable | Dans la journée ouvrée | Selon l’avancement |
Le vrai gain, ce n’est pas la finesse de la grille, c’est l’alignement qu’elle crée entre support, exploitation et métier. Dès que tout le monde parle le même langage, les escalades sont plus rapides et les discussions sont moins émotionnelles. Une bonne grille ne sert pourtant à rien si les bons outils n’acheminent pas l’information au bon endroit.
Les outils qui accélèrent vraiment la remise en service
En 2026, les plateformes les plus efficaces ne se contentent plus d’ouvrir des tickets. Elles classent, routent, alertent, suggèrent des réponses et centralisent la communication. Mais je reste prudent: l’automatisation aide énormément, à condition de ne pas transformer l’équipe en spectateur de son propre outillage.
| Catégorie d’outil | Ce qu’il doit faire | Limite fréquente |
|---|---|---|
| Ticketing ITSM | Centraliser le signalement, suivre le statut, garder la trace des actions | Devient vite un simple registre si les champs sont mal conçus |
| Supervision et alerting | Détecter plus tôt les anomalies et réduire le temps de découverte | Produit trop d’alertes si les seuils ne sont pas calibrés |
| Base de connaissances | Fournir des procédures, contournements et diagnostics déjà validés | Vieillit rapidement si personne ne la maintient après les incidents |
| Canal de crise | Synchroniser exploitation, support, métier et management dans un espace unique | Se transforme en bavardage si personne n’en pilote le rythme |
| Automatisation | Classer, router, résumer, déclencher un runbook ou proposer une solution | Peut accélérer une mauvaise décision si la validation humaine disparaît |
Ce qui me paraît le plus rentable, ce n’est pas l’outil « impressionnant », mais celui qui fait gagner les dix premières minutes: identification plus rapide, affectation claire, message initial propre, et contexte déjà rassemblé. Le reste suit beaucoup mieux quand ces fondations sont solides.
Même avec de bons outils, certaines habitudes dégradent la réponse plus vite que la panne elle-même.
Les erreurs qui rallongent les interruptions
J’observe souvent les mêmes erreurs, quel que soit le niveau de maturité de l’organisation. Elles ne viennent pas d’un manque de bonne volonté, mais d’un manque de discipline opérationnelle.
- Confondre symptôme et cause - on se précipite sur l’erreur visible sans vérifier ce qui l’a déclenchée.
- Multiplier les canaux - un ticket, un fil Teams, un mail, un appel et une messagerie parallèle créent de la dispersion.
- Ne pas nommer un propriétaire unique - plusieurs personnes « regardent » l’incident, mais personne ne décide vraiment.
- Fermer trop tôt - le service semble revenu, mais le contournement n’a pas été validé ou la régression n’a pas été vérifiée.
- Oublier l’historique récent - un déploiement, un changement réseau ou une modification de configuration auraient dû orienter le diagnostic.
- Sauter la revue post-incident - on considère que l’affaire est close alors que les apprentissages n’ont pas été capitalisés.
La revue post-incident n’a pas vocation à chercher un coupable. Elle sert à comprendre ce qui s’est passé, ce qui a fonctionné, ce qui a échoué et ce qu’il faut changer pour éviter de revivre la même séquence. Quand elle est bien menée, elle nourrit à la fois la fiabilité, la qualité de service et la confiance des équipes.
La qualité se mesure ensuite avec des chiffres, mais pas n’importe lesquels.
Mesurer la qualité sans tomber dans les indicateurs décoratifs
Un tableau de bord utile doit aider à décider, pas seulement à rassurer. Si les chiffres ne conduisent à aucune action concrète, ils finissent vite en décoration managériale.
Lire aussi : Digitalisation d'entreprise - Qualité, pas quantité !
Les métriques à suivre en priorité
| Métrique | Ce qu’elle mesure | Ce qu’elle vous apprend |
|---|---|---|
| MTTA | Temps moyen avant prise en charge | La réactivité réelle de l’équipe face au signal |
| MTTR | Temps moyen de restauration du service | La vitesse de remise en état et la qualité du diagnostic |
| Taux de réouverture | Part des tickets fermés puis rouverts | Si la résolution était vraiment durable |
| Respect des SLA | Part des incidents traités dans les délais contractuels | Si la promesse de service est tenue |
| Récurrence | Retour du même incident ou d’un incident similaire | Si la cause racine est encore présente |
| Répartition par catégorie | Types d’incidents les plus fréquents | Où se cachent les faiblesses récurrentes |
Le point le plus utile, selon moi, est de croiser les métriques plutôt que de les lire isolément. Un MTTR qui baisse alors que le taux de réouverture grimpe n’est pas une bonne nouvelle: cela peut vouloir dire que l’équipe ferme plus vite, mais pas forcément mieux. À l’inverse, un faible volume d’incidents ne dit rien si le service est peu utilisé ou si les utilisateurs contournent le support.
Quand ces indicateurs sont lisibles, on peut préparer le prochain incident au lieu de simplement subir le précédent.
Le plan que je mettrais en place avant le prochain incident majeur
Si je devais structurer un socle simple et robuste pour une équipe IT, je commencerais par cinq chantiers très concrets:
- Un propriétaire unique pour chaque incident critique, chargé de la coordination et de la communication.
- Une matrice de gravité courte, limitée à quatre niveaux maximum, avec des critères compréhensibles par le support et le métier.
- Un canal de crise unique pour éviter la dispersion des informations quand la pression monte.
- Des runbooks ciblés sur les dix incidents les plus fréquents ou les plus coûteux en temps.
- Une revue post-incident rapide, idéalement dans les 24 à 48 heures, tant que les faits sont encore frais.
- Un tableau de bord resserré avec quelques indicateurs réellement actionnables, pas vingt courbes qu’on ne regarde plus.
Ce trio fait généralement la différence plus vite que n’importe quel outil sophistiqué: priorisation claire, communication stable, apprentissage systématique. C’est là que la maturité opérationnelle se construit, incident après incident, sans surjouer la complexité.