
Dans un système d’information, le vrai problème n’est presque jamais le manque de données. Le point de rupture arrive quand ces signaux restent bruts, mal contextualisés ou impossibles à relier à une décision utile. C’est précisément ce que permet d’éclairer la chaîne entre donnée, information et connaissance, avec un angle très concret pour l’informatique et la cybersécurité.
Les points à retenir sur la hiérarchie des données et de la connaissance
- Une donnée brute n’a de valeur que si elle est qualifiée, contextualisée et reliée à un objectif métier ou sécurité.
- Dans un SOC ou une DSI, l’information utile naît de la corrélation, de la normalisation et du tri des signaux.
- La connaissance apparaît quand l’équipe sait interpréter un schéma, comprendre un risque et choisir la bonne réponse.
- En cybersécurité, la qualité, la gouvernance et la traçabilité comptent autant que les outils.
- Le modèle DIKW est un cadre pratique, pas une loi strictement linéaire.
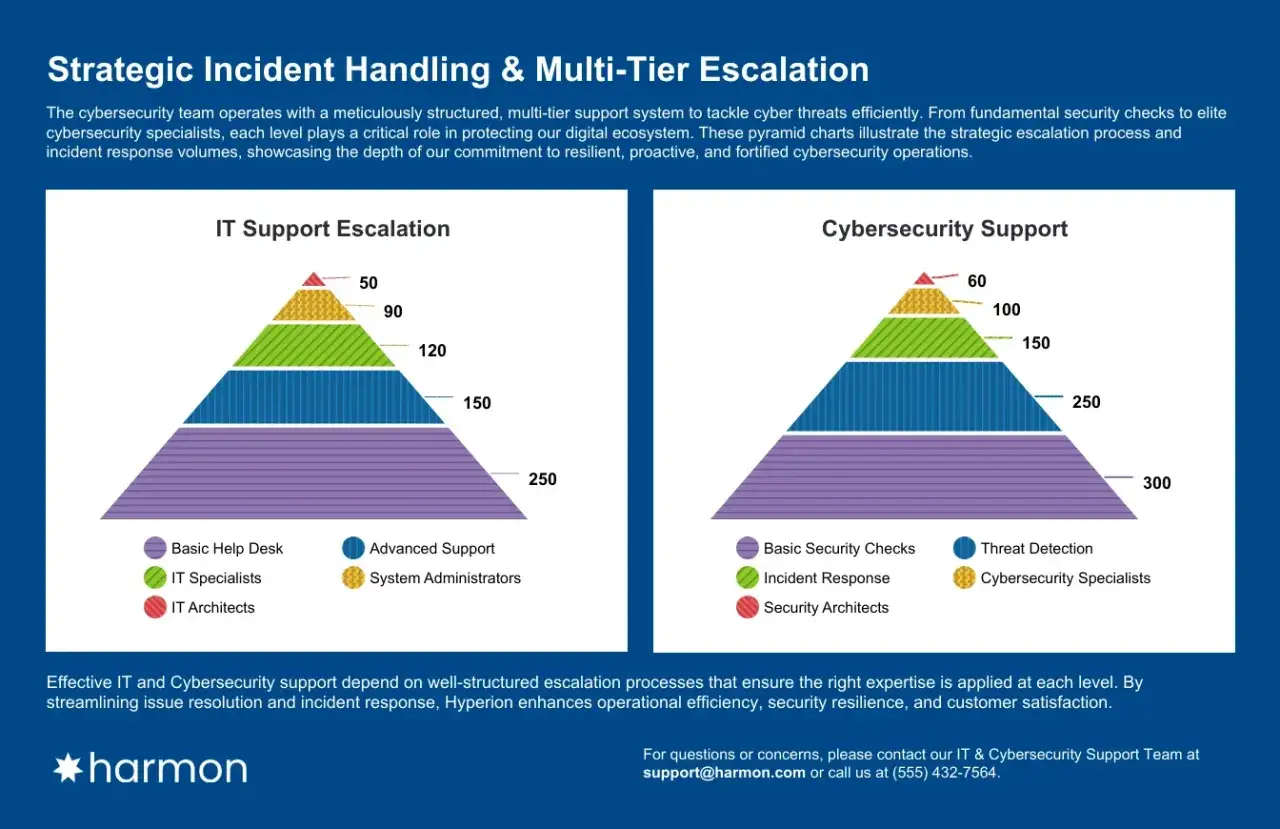
Comprendre la hiérarchie sans la réduire à un schéma scolaire
Je préfère lire la hiérarchie DIKW comme un continuum de transformation plutôt que comme une pyramide rigide. Une donnée est un fait brut, souvent isolé, comme une adresse IP, un horodatage ou un identifiant d’utilisateur. L’information apparaît quand ce fait prend du contexte et devient interprétable. La connaissance, elle, naît quand on sait relier l’information à une expérience, à un risque ou à une décision.
Dans la pratique, cette nuance change beaucoup de choses. Un journal de connexion répété 200 fois dans une console n’est pas encore une information. C’est seulement quand je le relie à un poste, à une plage horaire, à un compte sensible ou à une tentative d’accès inhabituelle que le signal devient exploitable.
| Niveau | Ce que cela représente | Exemple en cybersécurité | Ce que cela permet |
|---|---|---|---|
| Donnée | Fait brut, non interprété | Une ligne de log, une IP, un timestamp | Tracer, stocker, mesurer |
| Information | Fait mis en contexte | Échecs répétés sur un compte sensible depuis plusieurs pays | Qualifier, prioriser, alerter |
| Connaissance | Compréhension opératoire | Reconnaître une campagne de credential stuffing | Décider et agir plus vite |
| Décision | Réponse choisie à partir de la connaissance | Bloquer un compte, isoler une machine, lancer un incident | Réduire l’impact |
Cette lecture est utile parce qu’elle évite un écueil très courant dans les projets IT : croire qu’accumuler des données suffit à produire de la valeur. En réalité, la valeur naît du passage d’un niveau à l’autre, avec des règles de qualité, de contexte et de responsabilité. C’est ce passage qui mérite maintenant d’être regardé de près.
Pourquoi ce modèle compte autant en informatique et cybersécurité
En DSI comme en cybersécurité, le modèle DIKW aide à structurer une question simple : qu’est-ce que je veux vraiment savoir pour agir ? Si je ne la formule pas clairement, je me retrouve avec des tableaux de bord chargés, des alertes en cascade et peu de décisions réellement utiles.
Le cadre est particulièrement pertinent pour trois raisons. D’abord, il pousse à distinguer les données qui servent à observer de celles qui servent à décider. Ensuite, il rappelle qu’une équipe ne travaille pas seulement avec des volumes, mais avec de la qualité, des relations entre sources et une mémoire collective. Enfin, il relie la technique au pilotage : ce que je collecte doit finir par soutenir une action, un arbitrage ou une réduction du risque.
La CNIL rappelle d’ailleurs que la sécurité doit être proportionnée aux risques et s’appuyer sur des mesures techniques et organisationnelles adaptées au contexte. Dans les faits, cela veut dire qu’un système d’information ne se protège pas avec les mêmes règles s’il héberge des données RH, des données de santé ou des journaux d’accès techniques. Le modèle DIKW devient alors un bon outil de gouvernance, pas seulement un concept de gestion de l’information.
Autrement dit, plus le SI est complexe, plus la chaîne entre données, information et connaissance doit être explicitée. Sinon, on confond visibilité et maîtrise, ce qui est souvent le premier faux pas des équipes trop confiantes. C’est justement ce glissement qu’il faut éviter quand on travaille sur les logs, les alertes et les événements de sécurité.
Passer des données brutes à une information utile
Dans un environnement cyber, la matière première est abondante : logs de firewall, journaux Active Directory, événements cloud, traces EDR, alertes de messagerie, signaux réseau. Pris séparément, ces éléments n’expliquent pas grand-chose. L’information commence quand ils sont filtrés, agrégés et normalisés, puis reliés à une source, à un actif et à un niveau de criticité.
Le NIST décrit les SIEM comme des systèmes de journalisation centralisée qui analysent les logs, les stockent et passent par des étapes de filtrage, d’agrégation et de normalisation. C’est exactement ce qui fait la différence entre un simple entrepôt de traces et un outil capable d’éclairer une menace.Je vois souvent la même progression dans les organisations qui montent en maturité :
- on collecte d’abord les données sans trop savoir pourquoi,
- on construit ensuite des règles de corrélation pour réduire le bruit,
- on ajoute du contexte métier, comme la criticité d’un serveur ou le rôle d’un compte,
- on finit par isoler les signaux réellement exploitables par les analystes ou les équipes d’astreinte.
Un exemple concret : dix échecs d’authentification sur un compte standard sont un bruit courant. Dix échecs sur un compte d’administration, depuis plusieurs zones géographiques, pendant qu’un nouveau poste se connecte au VPN, ce n’est plus une simple donnée. C’est une information qui mérite une lecture sécuritaire immédiate. Et c’est précisément cette différence qu’une bonne chaîne de traitement doit mettre en évidence.
Le passage à la section suivante est naturel : une fois l’information construite, la vraie question devient celle de la connaissance partagée, celle qui rend l’équipe plus rapide et plus cohérente dans ses réponses.
Transformer l’information en connaissance opérationnelle
La connaissance n’est pas seulement ce que sait un expert dans sa tête. Dans un SI, elle doit être formalisée, réutilisable et transmissible. Sinon, elle disparaît au changement d’équipe, au turnover ou au moment où l’incident touche quelqu’un d’autre que l’analyste qui a déjà vu le problème.
C’est là que les playbooks, les runbooks, les procédures d’escalade et les retours d’expérience deviennent essentiels. Un playbook, c’est une procédure d’intervention standardisée. Un runbook, c’est la version plus opérationnelle, souvent pas à pas. Les deux servent à transformer une lecture de l’information en réponse cohérente.
Dans les équipes cyber que je trouve les plus solides, la connaissance prend généralement quatre formes :
- des schémas d’attaque reconnus, par exemple le phishing suivi d’une prise de contrôle de compte,
- des règles d’enrichissement, comme la présence d’un actif critique ou d’un utilisateur à privilèges,
- des seuils de décision, pour savoir quand escalader ou quand contenir immédiatement,
- des retours d’incidents, afin de capitaliser ce qui a vraiment fonctionné.
Ce que la cybersécurité change dans la hiérarchie
On oublie souvent que le pipeline data-information-knowledge ne sert pas uniquement à mieux analyser les menaces. Il doit aussi réduire l’exposition de l’organisation. Plus on collecte de traces, plus on augmente le volume de données sensibles à protéger, à tracer et à limiter.
La CNIL rappelle que la pseudonymisation est une mesure utile, mais qu’elle ne doit pas être confondue avec l’anonymisation. En clair, une chaîne de traitement peut très bien améliorer l’analyse sans faire disparaître le risque. Cela oblige à penser la sécurité dès la conception : qui voit quoi, combien de temps on conserve, et dans quel but précis.
Dans un contexte français, je recommande toujours de raisonner en trois couches :
- collecte minimale : ne stocker que les données nécessaires à la détection,
- accès contrôlé : réserver les logs détaillés aux personnes qui en ont besoin,
- traçabilité forte : journaliser aussi l’accès aux journaux, parce qu’un journal sans contrôle devient vite une faiblesse.
Il faut également garder en tête que la protection ne se limite pas au chiffrement ou à la pseudonymisation. Ce sont des briques utiles, mais pas une stratégie complète. Gouvernance, droits d’accès, segmentation, rétention, sensibilisation et gestion des incidents ont le même poids dans la pratique. Si cette couche de sécurité manque, la hiérarchie DIKW peut produire de la valeur analytique tout en créant un risque de conformité ou d’exposition inutile.
Une fois cette base posée, la question n’est plus seulement de comprendre le modèle, mais de savoir comment l’implémenter proprement dans un projet IT ou un SOC.
Comment l’appliquer dans un projet IT ou un SOC
Je conseille de partir non pas des outils, mais de la décision à soutenir. Si le besoin est de détecter plus vite un compte compromis, le dispositif n’a pas les mêmes exigences que si l’on veut simplement suivre l’état d’un parc applicatif. Le point de départ doit être un usage précis, mesurable et rattaché à une responsabilité claire.
Une mise en œuvre robuste peut suivre cette logique :
- Définir le cas d’usage prioritaire, par exemple la détection de compromission de comptes à privilèges.
- Identifier les sources réellement utiles, comme l’IAM, l’AD, le VPN, l’EDR et les journaux cloud.
- Normaliser les champs clés, pour comparer des événements hétérogènes sans perdre la cohérence.
- Enrichir avec le contexte métier, comme la criticité de l’actif, le propriétaire applicatif ou l’emplacement réseau.
- Créer des règles de corrélation et des playbooks, afin d’éviter que chaque alerte soit traitée de manière improvisée.
- Mesurer la qualité du flux, en suivant par exemple le taux de logs exploitables, le niveau de faux positifs et le délai de qualification.
Le piège classique consiste à empiler des alertes sans établir de hiérarchie. Dans ce cas, la chaîne s’arrête à l’information partielle. Pour qu’elle devienne connaissance, il faut une gouvernance, des règles stables et un effort régulier de mise à jour. C’est ce point de discipline qui mène naturellement à la dernière question utile : qu’est-ce que ce modèle change, au fond, pour une équipe IT ?
Ce que ce cadre apporte vraiment à une équipe IT
Le principal intérêt du modèle, à mes yeux, est simple : il oblige à distinguer ce qui est stocké, ce qui est compris et ce qui est actionnable. Cette distinction évite beaucoup de faux débats en réunion, notamment quand une équipe confond volume de collecte et maturité de pilotage.
Si je devais résumer l’approche en pratique, je dirais qu’une DSI gagne à se poser trois questions avant de multiplier les flux :
- quelle décision doit être rendue plus rapide ?
- quelle donnée apporte réellement un contexte de sécurité ou de pilotage ?
- quelle connaissance doit être capitalisée pour qu’un incident ne se répète pas de la même façon ?
Quand ces réponses sont claires, la chaîne entre données, information et connaissance devient un levier de performance. Quand elles ne le sont pas, on accumule des traces, des tableaux de bord et des alertes sans créer de meilleure décision. C’est là que le modèle garde toute sa pertinence : il ramène l’attention sur le sens, la priorité et la capacité d’agir.
Si je ne devais retenir qu’une idée, ce serait celle-ci : dans un SI moderne, la valeur ne vient pas de la donnée en elle-même, mais de la discipline avec laquelle on la transforme en information, puis en connaissance utile. C’est cette discipline qui fait la différence entre une organisation simplement équipée et une organisation vraiment pilotée.