
La qualité d’un service ne se dégrade presque jamais pour une seule raison. Dans un incident de production, un retard projet ou une non-conformité, les causes s’additionnent souvent: consigne floue, outil mal paramétré, données incomplètes, environnement instable, coordination imparfaite. La méthode des 5M sert précisément à remettre cet ensemble en ordre pour passer d’un symptôme à une cause probable, puis à une action corrective utile.
Les points clés à retenir pour analyser une cause racine avec méthode
- Le diagramme d’Ishikawa aide à structurer une analyse de cause racine sans tomber dans la culpabilisation.
- Les cinq familles couvrent la main-d’œuvre, la méthode, la matière, le matériel et le milieu.
- En contexte IT et projet, la “matière” devient souvent donnée, spécification, ticket ou contenu source.
- L’outil fonctionne mieux quand on l’appuie sur des faits, une chronologie et un plan d’action suivi.
- Les variantes 6M ou 7M peuvent aider, mais seulement si elles clarifient l’analyse au lieu de la diluer.
Pourquoi ce diagramme reste utile en qualité et en management
Je l’utilise surtout quand un problème revient, quand plusieurs équipes se renvoient la balle ou quand la première explication semble trop simple. L’intérêt du diagramme d’Ishikawa n’est pas de produire un schéma propre; c’est d’éviter deux pièges très classiques: la faute individuelle comme explication unique, et la solution appliquée trop vite sans compréhension du fond.Dans une démarche de management et qualité, l’outil crée un langage commun. Chacun peut contribuer sans devoir être expert en analyse statistique. On part d’un effet observable, puis on explore les familles de causes possibles pour distinguer ce qui relève du processus, de l’organisation, des moyens ou du contexte. C’est pour cela qu’il reste très efficace sur des sujets opérationnels: bug récurrent, retard de livraison, erreur de saisie, incident de service, non-conformité documentaire.
Je le recommande moins pour “prouver” qu’une seule cause explique tout. Il est beaucoup plus fort pour ouvrir l’enquête, recadrer la discussion et préparer une action corrective. Pour voir comment il se structure concrètement, il faut maintenant regarder les cinq familles une par une.
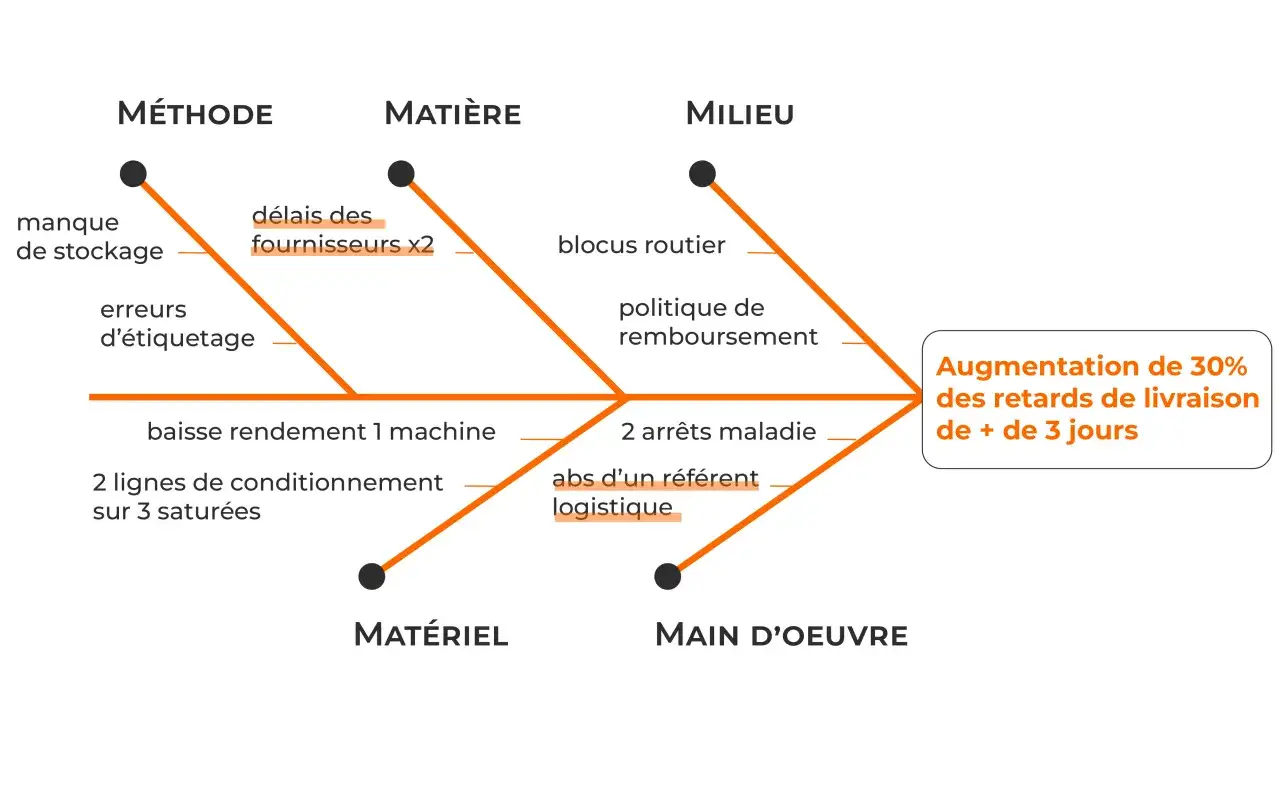
Les cinq familles de causes et ce qu’elles couvrent
Les 5M sont une grille de lecture, pas une recette rigide. En industrie, elles restent proches de leur définition d’origine. En IT, en gestion de projet ou dans les services, je les adapte légèrement pour garder leur utilité sans trahir leur logique.
| Famille | Ce que je regarde | Exemples en IT ou en projet | Piège courant |
|---|---|---|---|
| Main-d’œuvre | Compétences, charge, coordination, passation, fatigue, disponibilité | Équipe sous-dimensionnée, mauvaise transmission entre équipes, formation insuffisante | Réduire le problème à “manque de personnel” sans regarder l’organisation |
| Méthode | Procédures, validation, checklists, séquencement des tâches, règles de décision | Workflow de déploiement incomplet, validation absente, critères d’acceptation flous | Confondre la procédure écrite avec la pratique réelle |
| Matière | Données, spécifications, inputs, documents, contenus source, pièces ou informations de base | Exigences incomplètes, tickets mal qualifiés, données d’entrée erronées | Oublier que des données médiocres produisent presque toujours des sorties médiocres |
| Matériel | Outils, serveurs, postes, réseau, scripts, environnement de test, intégrations | Pipeline CI/CD instable, environnement de recette non aligné, outil de suivi défaillant | Limiter “matériel” aux objets physiques alors qu’en numérique il inclut aussi l’outillage |
| Milieu | Contexte de travail, contraintes, délais, dépendances, réglementation, environnement | Fenêtre de mise en production trop courte, dépendance fournisseur, multi-sites, pression calendrier | Ignorer le cadre réel dans lequel le problème se produit |
Quand le sujet devient plus fin, j’ajoute parfois une couche “mesure” si les indicateurs, les logs ou les KPI jouent un rôle central, ou une couche “management” si la gouvernance, l’arbitrage et la priorisation sont au cœur du dysfonctionnement. Mais je le fais avec parcimonie: trop de familles noient l’analyse au lieu de l’éclairer.
Une fois ces catégories posées, le vrai travail commence: relier chaque branche à des faits, pas à des impressions. C’est exactement ce qu’il faut faire dans la phase suivante.
Construire une analyse utile sans la transformer en débat interminable
Sur un cas simple, je vise souvent un atelier de 30 à 45 minutes. Pour un problème multi-équipes, je peux aller jusqu’à une à trois heures, mais seulement si l’on dispose de données minimales. Au-delà, on quitte vite l’analyse pour entrer dans l’opinion pure.
- Formuler le problème de manière factuelle. Je décris l’effet observé, sa date, son périmètre et son impact. “Le déploiement a échoué” est trop vague; “le déploiement de 21 h a généré 18 erreurs API pendant 12 minutes” est exploitable.
- Rassembler les éléments de contexte. Je note la chronologie, les logs, les tickets, les versions, les validations, les écarts de charge ou les changements récents.
- Remplir les branches des 5M. Je liste d’abord les causes possibles sans filtrer trop tôt. L’objectif est d’être exhaustif avant d’être sélectif.
- Tester la solidité des causes. Une cause n’a de valeur que si elle est observable, documentée ou confirmée par plusieurs indices convergents.
- Creuser la branche la plus crédible. J’associe souvent les 5M à la méthode des 5 Pourquoi pour descendre d’un symptôme vers une cause racine plus profonde.
- Transformer l’analyse en plan d’action. Chaque action doit avoir un responsable, une échéance et un critère de succès mesurable.
Les erreurs que je vois le plus souvent sont assez prévisibles: écrire une solution à la place d’une cause, mettre toute la pression sur la personne au lieu du système, ou empiler vingt causes sans hiérarchie. Dans ces cas-là, le diagramme devient un décor. Bien utilisé, il oblige au contraire à arbitrer.
Cette logique change beaucoup de choses quand on l’applique à des situations très concrètes de management IT ou de gestion de projet.
Deux cas concrets qui montrent la valeur de l’outil
Dans les équipes techniques, j’aime traduire les 5M en leviers opérationnels. Ce n’est pas un exercice théorique: on veut comprendre ce qui a réellement bloqué le flux et ce qu’il faut corriger pour éviter la répétition.
| Situation | Causes dominantes | Ce que l’analyse fait apparaître | Action la plus utile |
|---|---|---|---|
| Déploiement interrompu en production | Méthode, matériel, milieu | Checklist incomplète, environnement de recette non fidèle, fenêtre de change trop courte | Standardiser le go/no-go, fiabiliser l’environnement et élargir le contrôle de préproduction |
| Retard répété sur un projet de transformation digitale | Main-d’œuvre, méthode, matière | Rôles flous, dépendance à des livrables mal définis, informations d’entrée arrivant trop tard | Clarifier les responsabilités, figer le périmètre utile et sécuriser les jalons amont |
| Tickets support traités trop lentement | Main-d’œuvre, matière, milieu | Base de connaissance pauvre, catégorisation approximative, surcharge ponctuelle de l’équipe | Améliorer la qualification, enrichir les procédures et répartir le triage plus tôt |
Ce que je trouve le plus intéressant dans ces cas-là, c’est qu’on quitte rapidement la logique du “qui a fait l’erreur ?” pour passer à “qu’est-ce qui dans le système a rendu l’erreur possible ?”. Cette bascule change la qualité des actions correctives. Elle change aussi le niveau d’adhésion des équipes, parce qu’on ne cherche plus un coupable, on cherche un levier.
Mais l’outil n’est pas magique. Il a ses limites, et les connaître évite de lui demander ce qu’il ne peut pas donner seul.
Les limites à connaître avant de conclure trop vite
Le diagramme fonctionne très bien pour structurer une réflexion collective, mais il montre vite ses limites quand le problème est très quantitatif, très chronologique ou déjà très documenté. Dans ces cas-là, je m’en sers comme point de départ, pas comme méthode unique.
| Quand le 5M atteint sa limite | Complément utile | Ce que cela apporte |
|---|---|---|
| Le problème est récurrent et les causes s’empilent | 5 Pourquoi | Remonter progressivement d’un effet visible à une cause plus profonde |
| Plusieurs causes sont possibles, mais il faut prioriser | Pareto | Identifier les causes qui pèsent le plus sur le résultat |
| Le flux de travail est flou ou mal découpé | Cartographie de processus | Voir où le défaut naît réellement dans la chaîne |
| Le risque futur compte autant que l’incident passé | AMDEC ou logique de prévention | Évaluer la criticité et anticiper les modes de défaillance |
Je pose aussi une règle simple: si une cause n’est pas observable, elle reste une hypothèse, pas une vérité. C’est une discipline utile, surtout quand l’équipe veut aller trop vite vers la solution. Une bonne analyse n’est pas celle qui produit le plus de branches, c’est celle qui produit les bonnes décisions.
La suite logique, justement, consiste à verrouiller ce qui transforme l’analyse en amélioration durable.
Ce que je verrouille avant de clore l’analyse
Avant de considérer le travail terminé, je vérifie systématiquement cinq points. Sans eux, le diagramme reste un atelier de discussion; avec eux, il devient un vrai outil de management de la qualité.
- Une cause prioritaire clairement retenue, pas dix causes traitées au même niveau.
- Un responsable unique pour chaque action corrective.
- Une échéance courte et réaliste, sinon l’action se dilue.
- Un indicateur simple pour mesurer le changement avant et après.
- Une date de revue pour confirmer que le problème ne revient pas.
Quand ces cinq éléments sont en place, le cadre 5M devient vraiment utile: il aide à stabiliser un processus, à réduire les incidents et à capitaliser les apprentissages. C’est cette rigueur-là qui fait la différence entre une analyse élégante sur le papier et une amélioration qui tient dans la durée.